
Многопоточное программирование
Итак, что же такое многопоточное программирование (MultiThreading, MT)? И чем оно отличается от обычного, однопоточного (Single-Threaded, ST) программирования?
К сожалению, с точки зрения абсолютного большинства программистов и авторов (а порою и весьма уважаемых и компетентных в своей области авторов) MT -- это все то же самое обычное программирование, разве что щедро усыпанное невообразимым количеством mutex-ов "для корректности". В типичной настольной книжке вам приведут стандартный пример с двумя потоками (т.е. thread-ами), одновременно изменяющими значение одной и той же переменной, лихо вылечат ошибку посредством пресловутого mutex-а, а заодно и растолкуют что такое deadlock и почему много mutex-ов тоже плохо.
Многопоточное программирование определяется дизайном приложения, который РАЗРЕШАЕТ параллельное одновременное исполнение.
Вдумайтесь! Не "приложение, исполняющее несколько потоков", а прежде всего "дизайн, разрешающий параллельное исполнение". Даже не требующий! Кстати, использование блокировок не разрешает параллельное исполнение, т.е. использование mutex-ов, вообще говоря, не дает возможности получить хороший MT дизайн!
Не удержусь и отмечу еще один архитектурный изъян многострадальной Java (и ее недалеких клонов), содержащей по mutex-у в каждом объекте и даже предоставляющей ключевое слово synchronized, позволяющее вам легко и удобно создавать методы, параллельное одновременное исполнение которых невозможно. Да-да, все именно так и есть, как оно выглядит: языки и технологии программирования зачастую проектируются технически некомпетентными в этой области специалистами!
За что же досталось mutex-у?!" -- спросит меня опешивший читатель. "Неужели примитивы синхронизации вроде mutex-ов, semaphore-ов и т.п. вообще не нужны в MT приложениях?!" Ну, что же: они безусловно нужны для реализации некоторых, крайне низкоуровневых интерфейсов, но в обычном коде им просто нет места. Типичным примером правильного MT дизайна является приложение, в котором потоки извлекают из очереди сообщения для обработки и помещают в нее свои сообщения, обработка которых может быть произведена параллельно. Вот для реализации подобного рода очереди они и предназначены, а обычный код имеет дело только лишь с ее интерфейсом. К тому же, для случая ST приложения класс-реализация данного интерфейса никаких mutex-ов, очевидно, не должен использовать.
Судя по всему, идеальным MT приложением является приложение, в котором потоки вообще избегают какой бы то ни было синхронизации и, следовательно, могут исполняться без всяких взаимных задержек. На первый взгляд такая ситуация кажется абсурдной, но если в качестве некоего "логически единого" приложения представить себе два ST Web-сервера, работающих на двух разных машинах и отдающих пользователям один и тот же статический контент из собственных локальных копий, то мы имеем дело как раз с тем самым идеальным случаем, когда добавление второго, абсолютно независимого потока (факт. запуск на другой машине зеркального сервера) в буквальном смысле удваивает общую производительность комплекса, без оговорок.
Но в реальных MT приложениях потоки работают в кооперации друг с другом (и операционной системой, конечно же) и, следовательно, вынуждены синхронизировать свою работу. А синхронизация неизбежно приводит к задержкам, на время которых независимое одновременное исполнение приостанавливается. Так что количество и продолжительность промежутков синхронизации в правильно спроектированном MT приложении должна стремиться к относительному нулю, т.е. быть исчезающе малой по сравнению с общим временем работы потока.
Описанный выше дизайн потоки+очередь является классическим примером правильного MT приложения, если конечно потоки не пытаются передавать друг другу настолько малые подзадачи, что операция по помещению/извлечению сообщения из очереди занимает больше времени, чем обработка подзадачи самим потоком "на месте". Дизайн потоки+очередь мы и будем использовать в нашем учебном примере mtftext, равно как и в следующих за ним приложениях.
Работа с памятью
Для начала поговорим о подводных камнях C++ применительно к MT программированию. На первый взгляд может показаться, что написанные на C++ потоки, не изменяющие одни и те же данные одновременно, могут работать абсолютно независимо и параллельно. К сожалению, это не совсем так: основной проблемой является стандартный распределитель памяти, т.е. операторы new/delete. Суть проблемы в том, что приложение получает свободные блоки памяти от системы и выдает их части потокам по требованию, т.е. в процессе своей работы потоки вынуждены изменять одни и те же структуры данных (глобальные цепочки свободных блоков) и, следовательно, синхронизация их работы неизбежна.
Прямым решением данной проблемы является повсеместное явное использование собственного распределителя памяти, кэширующего полученные от глобального распределителя блоки. Т.е. своего объекта mem_pool для каждого отдельного потока (как минимум). Конечно, с точки зрения удобства кодирования повсеместное мелькание ссылок mem_pool& трудно назвать приемлемым -- стоит ли овчинка выделки? Давайте разберемся с помощью следующего примера:
#include <list>
#include <vector>
#include <stdio.h>
#include <time.h>
#include <ders/stl_alloc.hpp>
#include <ders/thread.hpp>
using namespace std;
using namespace ders;
const int N=1000;
const int M=10000;
void start_std(void*)
{
list<int> lst;
for (int i=0; i < N; i++) {
for (int j=0; j < M; j++) lst.push_back(j);
for (int j=0; j < M; j++) lst.pop_front();
}
}
void start_ders(void*)
{
mem_pool mp;
stl_allocator<int> alloc(mp);
list<int, stl_allocator<int> > lst(alloc);
for (int i=0; i < N; i++) {
for (int j=0; j < M; j++) lst.push_back(j);
for (int j=0; j < M; j++) lst.pop_front();
}
}
int main(int argc, char** argv)
{
if (argc!=3) {
m1:
fprintf(stderr, "main num_threads std|ders");
return 1;
}
int numThr=atoi(argv[1]);
if ( !(numThr>=1 && numThr<=100) ) {
fprintf(stderr, "num_threads must be in [1, 100]");
return 1;
}
void (*start)(void*);
if (strcmp(argv[2], "std")==0) start=start_std;
else if (strcmp(argv[2], "ders")==0) start=start_ders;
else goto m1;
clock_t c1=clock();
mem_pool mp;
vector<sh_thread> vthr;
for (int i=0; i<numThr; i++) vthr.push_back(new_thread(mp, start, 0));
for (int i=0; i<numThr; i++) vthr[i]->join();
clock_t c2=clock();
printf("%d\t%d\t%s\n", numThr, int(c2-c1), argv[2]);
return 0;
}
Программа запускает заданное в командной строке количество потоков и в каждом из них выполнят фиксированное количество вставок/удалений элементов в стандартный список. Отличие функции start_ders состоит в том, что вместо стандартного аллокатора по умолчанию lst использует аллокатор на основе mem_pool.
Производительность
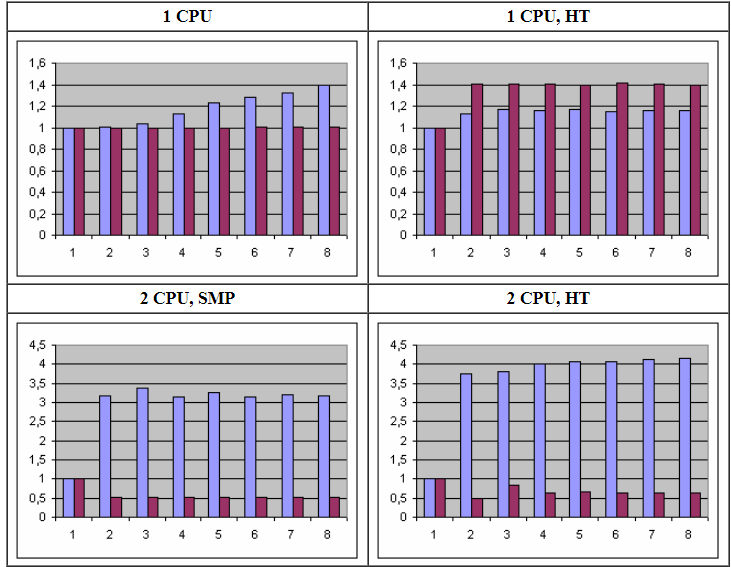
Усредненные результаты запусков (на разных компьютерах и системах) представлены в таблице:
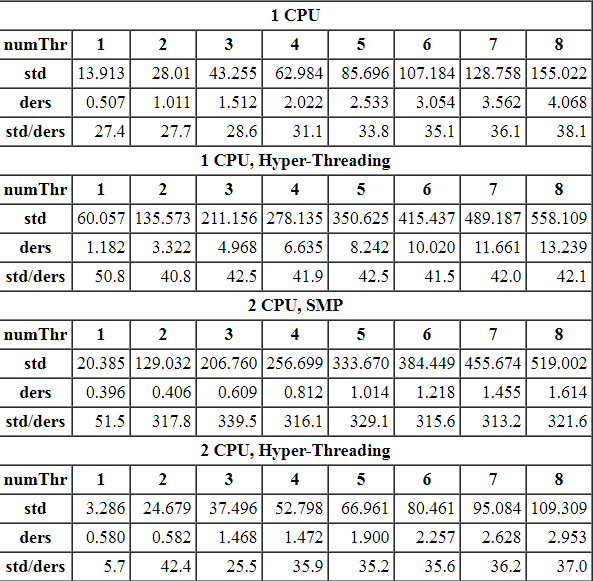
Время работы указано в секундах, а в строке std/ders приведено отношение времени работы функций -- именно те данные, которые нас и интересуют. Следующая ниже диаграмма показывает их в более наглядной форме:
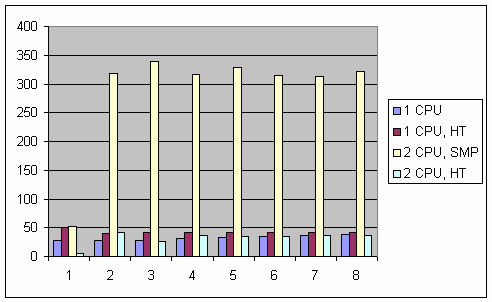
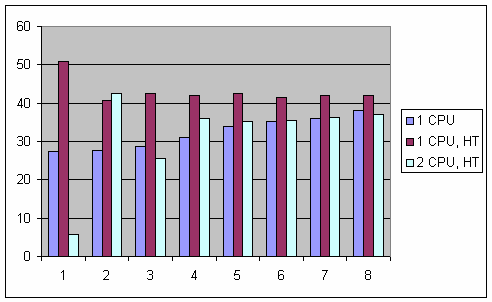
Удивительно, но факт: относительный выигрыш 2 CPU, SMP компьютера настолько велик, что даже имеет смысл привести ту же самую диаграмму без его участия:
Проведем краткий анализ:
Функция start_ders, использующая аллокатор на основе mem_pool работает в десятки и даже сотни (!!!) раз быстрее. Так что "повсеместное мелькание" mem_pool& является, мягко говоря, оправданным. И даже более того! Учитывая ТАКУЮ разницу эффективности, вопрос должен ставиться совершенно иначе:
Производительность стандартных STL контейнеров в MT приложениях может быть катастрофически неприемлемой!
Относительное время работы существенным образом варьируется, пока количество рабочих потоков не достигнет количества доступных (логических) процессоров:1 CPU В силу того, что потокам доступен всего лишь один процессор, никаких вариаций не может быть видно: отношение сразу же начинает нарастать и нарастает практически линейно на протяжении всего графика (т.е. по мере увеличения количества рабочих потоков).
1 CPU, Hyper-Threading. В этом случае система пытается вести себя так, как будто приложению доступно два независимых "логических" процессора, а не один (компетентные источники утверждают, что максимум того, что мы можем получить с точки зрения производительности это примерно 1.3 независимых процессора, не более). Как можно видеть, наибольший относительный выигрыш в 51 раз получается при одном рабочем потоке. Затем он падает до 41 раза на двух потоках и начиная с трех потоков стабилизируется около 42-х.
2 CPU, SMP. А здесь мы уже имеем два полноценных независимых процессора. Даже на единственном рабочем потоке относительный выигрыш в 51.5 раз уже превосходит результаты всех остальных компьютеров, но на двух и более потоках (с появлением реальной синхронизации и неизбежно вызываемых ею задержек) выигрыш скачкообразно увеличивается до 318 (!!!) раз и далее стабилизируется около этого значения. Данный случай является безусловным лидером нашего хитпарада!
2 CPU, Hyper-Threading. В отличии от второго случая с единственным HT процессором, два HT процессора на одном рабочем потоке показывают минимальный выигрыш -- всего 6 раз. Но аналогично третьему варианту, на двух потоках выигрыш скачкообразно (и примерно в те же 6-7 раз) увеличивается до 42, но на трех припадает, до 26. С четырех и далее потоков прослеживается более-менее стабильный результат в 36 раз, возможно увеличивающийся по мере роста количества рабочих потоков. По исчерпании всех свободных процессоров ни о каком параллелизме уже не может быть речи, что все четыре рассмотренных графика в полной мере нам и продемонстрировали.
Масштабируемость
Но одной лишь производительностью характеристики MT приложений не заканчиваются. Еще одним ключевым параметром является масштабируемость (scalability), т.е. способность приложения увеличивать производительность адекватно количеству задействованных ресурсов. Время исполнения не использующего параллелизм ST приложения будет увеличиваться пропорционально заданному объему работы, в то время как правильно спроектированное MT приложение будет способно выполнять работу на всех доступных процессорах параллельно и в идеальном случае увеличение количества процессоров, например, в два раза должно в два раза уменьшать затрачиваемое на тот же объем работы время.
В нашем случае каждый запущенный поток должен выполнить один и тот же объем работы, т.е. при отсутствии параллелизма (напр. когда приложению доступен только один процессор) общее время работы приложения будет увеличиваться (не менее чем) прямо пропорционально количеству рабочих потоков, задаваемых параметром numThr. С другой стороны, в случае идеального параллелизма, время работы приложения должно уменьшиться в количество раз, равное количеству задействованных процессоров.
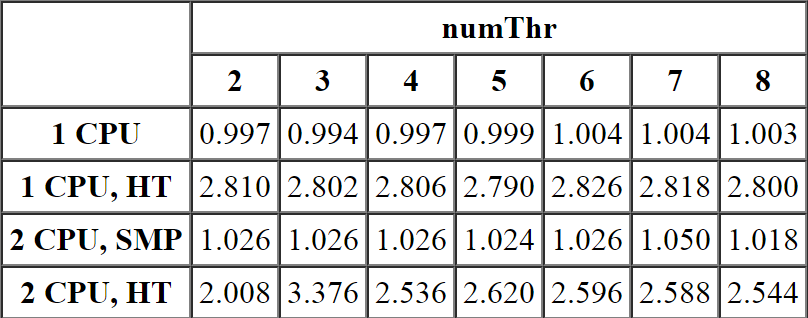
Разобраться с масштабируемостью нам поможет следующая таблица. Значения в ячейках рассчитаны по формуле t(N)/t(1)/N. Т.е. время работы приложения с количеством рабочих потоков равным N делится на время, затраченное одним потоком, а затем на количество потоков. Тем самым мы измеряем относительное отклонение времени работы нашего MT приложения от обычного однопоточного варианта (факт. ST приложения).
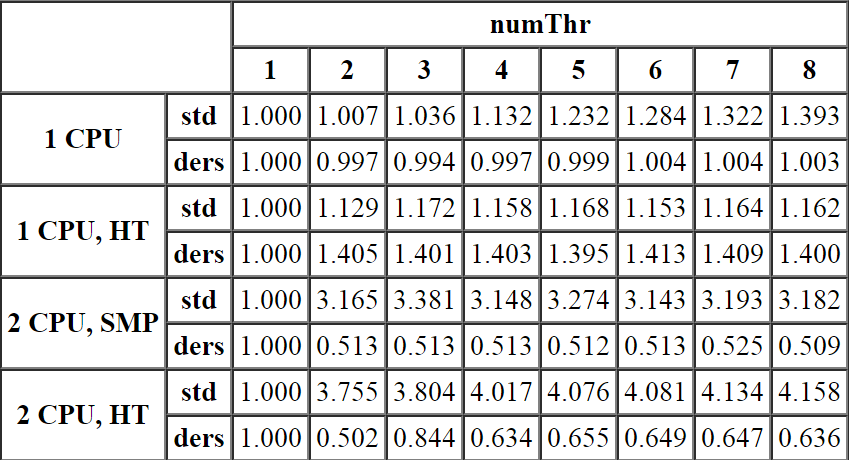
Ну а выглядят данные следующим образом:
Как можно видеть,
1 CPU Функция start_ders демонстрирует практически идеальное соответствие эталонному однопоточному варианту, т.е. присутствующие механизмы синхронизации не вызывают заметных накладных расходов. С другой стороны, накладные расходы функции start_std практически линейно увеличиваются с ростом количества задействованных потоков, достигая в итоге значения 1.4.
1 CPU, Hyper-Threading. Накладные расходы функции start_std увеличиваются до трех задействованных потоков, а затем стабилизируются возле значения 1.2. Накладные расходы функции start_ders стабилизируются уже на двух потоках, но на более высоком значении 1.4. Т.е. в этом случае несмотря на заметно более высокую скорость работы (42 раза, т.е. 4200%), масштабируемость start_ders примерно на 17% хуже start_std, т.е.
Использование нескольких потоков на Hyper-Threading архитектуре для такого рода задач является неоправданным, т.к. однопоточное приложение заведомо быстрее справится с объемом данных!
2 CPU, SMP. А это первый случай, в котором скорость работы приложения превышает скорость эталонного однопоточного варианта (отношение времени работы меньше единицы). Функция start_std демонстрирует более-менее стабильную масштабируемость около значения 3,2 раза. При этом значения нечетного количества потоков чуть больше, а четных -- чуть меньше данной величины (вероятно, худшая масштабируемость нечетного количества потоков связана с необходимостью планирования их работы на четном количестве процессоров). С другой стороны, функция start_ders показывает практически идеальные 0,5+дельта, т.е. удвоение количества процессоров в два раза уменьшило затрачиваемое на работу время.
2 CPU, Hyper-Threading. Еще один малоприятный случай: хоть масштабируемость функции start_ders и меньше единицы, но демонстрируемый в среднем результат 0,65 заметно хуже предыдущего варианта и уж точно никак не похож на 0,25, которого можно было бы ожидать от полноценного 4 CPU, SMP компьютера.
Масштабируемость Hyper-Threading архитектур
А сейчас проанализируем продемонстрированные особенности масштабируемости Hyper-Threading архитектур -- здесь есть над чем задуматься! Напомню, что с точки зрения маркетинга использование HT процессора как бы удваивает количество доступных CPU, т.е. 1 CPU, HT компьютер должен вести себя как 2 CPU, SMP, а 2 CPU, HT -- как 4 CPU, SMP, а ожидаемая масштабируемость функции start_ders на 2 CPU, SMP и 4 CPU, SMP составляет 0,5 и 0,25 соответственно. Следующая ниже таблица показывает насколько ожидаемая масштабируемость отличается от реальной:
вы, все очень печально: масштабируемость HT вариантов приблизительно в 2,6-2,8 раз хуже ожидаемой. Данная цифра тем более любопытна, что даже если считать один HT процессор не за два, а один CPU, то полученные значения 1,3-1,4 все равно больше единицы, т.е.
С точки зрения масштабируемости один Hyper-Threading процессор не только хуже двух обычных -- он хуже даже одного!Работа с файлами
Второй пример более приближен к жизни и предназначен для измерения относительной производительности MT приложения, работающего с файлами. Работа с файлами главным образом "упирается" в производительность файловой подсистемы ОС, так что прикладной код, использующий системные вызовы ввода/вывода, вряд ли покажет существенную разницу производительности...
Как известно, стандартные потоки ввода/вывода C++ работают существенно медленнее потоков ввода/вывода C. Но, к сожалению, даже C-шные потоки FILE не подходят для MT приложений, т.к. все операции над ними обязаны быть thread-safe по умолчанию, а быстрые варианты функций getc() и putc(), не использующие пресловутые mutex-ы, имеют другие имена: getc_unlocked() и putc_unlocked() соответственно. Тем самым, написание кода, одинаково хорошо работающего как в ST, так и в MT окружении становится невозможным.
Главным образом, для решения этой проблемы и был создан класс file, не использующий блокировок:
#include <memory>
#include <vector>
#include <stdio.h>
#include <time.h>
#include <ders/file.hpp>
#include <ders/text_buf.hpp>
#include <ders/thread.hpp>
using namespace std;
using namespace ders;
const int BUF_SIZE=64*1024;
struct MainData {
const char* fname;
MainData(const char* fn) : fname(fn) {}
};
struct ThreadData {
MainData* md;
int n;
ThreadData(MainData* md_, int n_) : md(md_), n(n_) {}
};
void start_std(void* arg)
{
ThreadData* td=(ThreadData*)arg;
auto_ptr<ThreadData> guard(td);
mem_pool mp;
file err(mp, fd::err);
FILE* fin=fopen(td->md->fname, "rb");
if (!fin) {
err.write(text_buf(mp)+"Can't open "+td->md->fname+'\n');
return;
}
sh_text oname=text_buf(mp)+td->md->fname+'.'+td->n;
FILE* fout=fopen(oname->c_str(), "wb");
if (!fout) {
err.write(text_buf(mp)+"Can't create "+oname+'\n');
fclose(fin);
return;
}
setvbuf(fin, 0, _IOFBF, BUF_SIZE);
setvbuf(fout, 0, _IOFBF, BUF_SIZE);
for (int ch; (ch=fgetc(fin))!=EOF; )
fputc(ch, fout);
fclose(fout);
fclose(fin);
}
void start_ders(void* arg)
{
ThreadData* td=(ThreadData*)arg;
auto_ptr<ThreadData> guard(td);
mem_pool mp;
file err(mp, fd::err);
file fin(mp);
if (!fin.open(td->md->fname, file::rdo, 0)) {
err.write(text_buf(mp)+"Can't open "+td->md->fname+'\n');
return;
}
sh_text oname=text_buf(mp)+td->md->fname+'.'+td->n;
file fout(mp);
if (!fout.open(oname, file::wro, file::crt|file::trnc)) {
err.write(text_buf(mp)+"Can't create "+oname+'\n');
return;
}
buf_reader br(mp, fin, BUF_SIZE);
buf_writer bw(mp, fout, BUF_SIZE);
for (int ch; (ch=br.read())!=-1; )
bw.write(ch);
}
int main(int argc, char** argv)
{
mem_pool mp;
file err(mp, fd::err);
file out(mp, fd::out);
if (argc!=4) {
m1:
err.write("main file num_threads std|ders");
return 1;
}
int numThr=atoi(argv[2]);
if ( !(numThr>=1 && numThr<=100) ) {
err.write("num_threads must be in [1, 100]");
return 1;
}
void (*start)(void*);
if (strcmp(argv[3], "std")==0) start=start_std;
else if (strcmp(argv[3], "ders")==0) start=start_ders;
else goto m1;
MainData md(argv[1]);
clock_t c1=clock();
vector<sh_thread> vthr;
for (int i=0; i<numThr; i++)
vthr.push_back(new_thread(mp, start, new ThreadData(&md, i)));
for (int i=0; i<numThr; i++) vthr[i]->join();
clock_t c2=clock();
out.write(text_buf(mp)+numThr+'\t'+int(c2-c1)+'\t'+argv[3]+'\n');
return 0;
}
Пример запускает заданное количество потоков, в каждом из которых создается копия указанного в командной строке файла посредством выбранной функции: start_std() или start_ders(). Потоками используется посимвольное копирование через буфер размера BUF_SIZE.
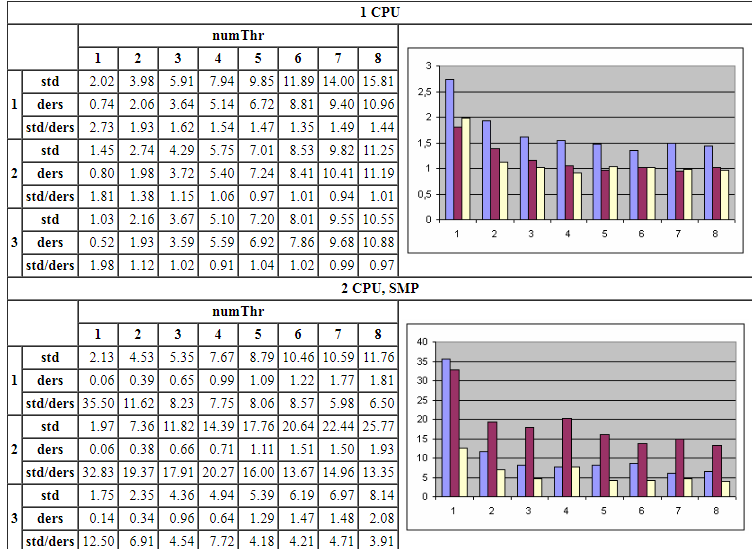
В таблице представлены усредненные результаты запуска (в секундах) на трех разных компиляторах с файлом десятимегабайтного размера:
Как можно видеть,
1 CPU Функция start_ders работает быстрее в 1.4-2.7, 0.9-1.8 и 0.9-2.0 раз для каждого из трех компиляторов соответственно. Вероятно, значения меньше 1.0 (т.е. небольшое замедление, а не ускорение работы) являются следствием ошибок измерения, неизменно возникающих при замерах времени работы приложений, интенсивно работающих с файловой подсистемой.
2 CPU, SMP. В данном случае преимущество start_ders, так скажем, более очевидно: в 6.0-35.5, 13.4-32.9 и 4.2-12.5 раз соответственно!
Во всех случаях наибольший выигрыш производительности получен на единственном рабочем потоке, когда встроенная синхронизация функций getc() и putc() полностью невостребована. А по ходу увеличения количества рабочих потоков выигрыш постепенно уменьшается в силу того, что узким местом масштабируемости является сама файловая подсистема, не поддерживающая эффективного распараллеливания запросов ввода/вывода в силу своего устройства.
Таким образом,
Использование класса ders::file способно ускорить выполнение MT приложений в десятки раз!
Конечно, это не сотни раз предыдущего примера, но, тем не менее, даже подобная "скромная" разница производительности заставляет пристально присмотреться к устройству стандартной библиотеки C++: любопытно, задумывались ли ее проектировщики об эффективности работы в многопоточной среде?
И, в свете всего вышеперечисленного, у нас есть вполне определенный ответ на вопрос "Оправдано ли создание своих собственных классов, предоставляющих альтернативную реализацию давным-давно известных стандартных функций ввода/вывода?": увы, "не мона, а нуна"!