
- Введение в стандартную библиотеку шаблонов
- Обзор STL
- Контейнерные классы
- Векторы
- Доступ к вектору с помощью итератора
- Вставка и удаление элементов из вектора
- Сохранение в векторе объектов класса
- О пользе итераторов
- Списки
- Сортировка списка
- Объединение одного списка с другим
- Хранение в списке объектов класса
- Отображения
- Хранение в отображении объектов класса
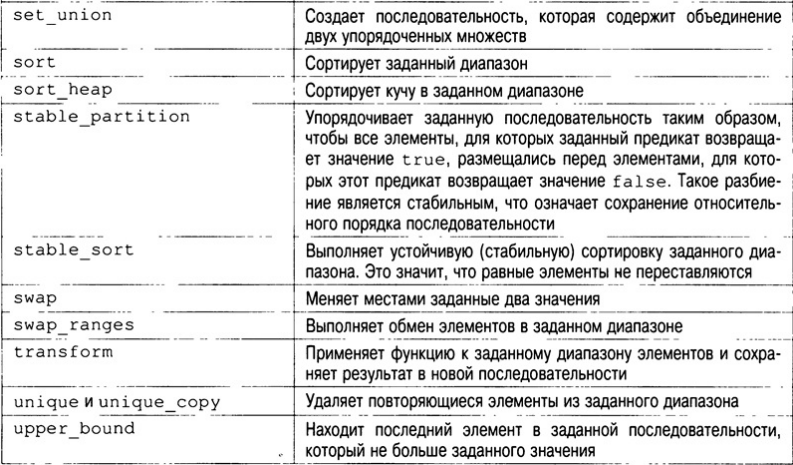
- Алгоритмы
- Удаление и замена элементов
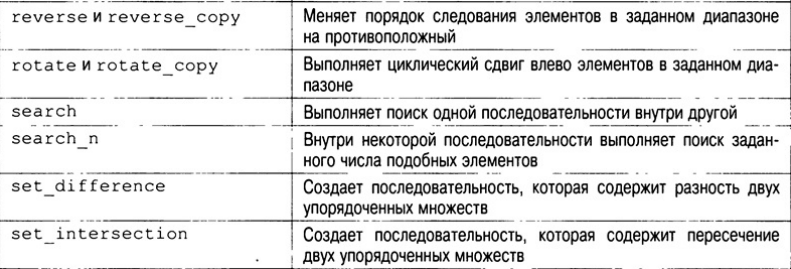
- Реверсирование последовательности
- Преобразование последовательности
- Исследование алгоритмов
- Класс string
- Обзор функций-членов класса string
- Основные манипуляции над строками
- Поиск в строке
- Сравнение строк
- Получение строки с завершающим нулем
- Хранение строк в других контейнерах
- И еще об STL
Введение в стандартную библиотеку шаблонов
Материал этой главы составляет то, что многие считают самым важным добавлением в C++ за последние годы. Речь идет о стандартной библиотеке шаблонов (Standard Template Library — STL). Именно включение библиотеки STL в C++ было основным событием, которое обсуждалось в период стандартизации C++. Библиотека STL предоставляет шаблонные классы и функции общего назначения, которые реализуют многие популярные и часто используемые алгоритмы и структуры данных. Например, она включает поддержку векторов, списков, очередей и стеков, а также определяет различные функции, обеспечивающие к ним доступ. Поскольку библиотека STL состоит из шаблонных классов, алгоритмы и структуры данных могут быть применены к данным практически любого типа.
Библиотека STL — это набор шаблонных классов и функций общего назначения. Библиотека STL— это результат разработки программного обеспечения, который вобрал в себя одни из самых сложных средств языка C++. Чтобы понимать содержимое библиотеки STL и уметь им пользоваться, необходимо освоить весь материал, изложенный в предыдущих главах. Особенно хорошо нужно ориентироваться в шаблонах. Откровенно говоря, шаблонный синтаксис, который описывает STL, может поначалу испугать, хотя он выглядит сложнее, чем есть на самом деле. Несмотря на то что материал этой главы не труднее остального в этой книге, не следует огорчаться, если что-то на первый взгляд вам покажется непонятным. Немного терпения при рассмотрении примеров — и вскоре вы поймете, что за непривычным синтаксисом скрывается строгая простота STL.
STL — довольно большая библиотека, и все ее средства невозможно изложить в одной главе. Полное описание библиотеки STL со всеми ее нюансами и методами программирования заняло бы целую книгу. Цель представленного здесь обзора — познакомить вас с основными операциями, принципами проектирования и основами STLпрограммирования. Освоив материал этой главы, вы сможете легко изучить остальную часть библиотеки STL самостоятельно.
В этой главе также описан еще один важный класс C++ — класс string. Он предназначен для определения строкового типа данных, который позволяет обрабатывать символьные строки во многом подобно тому, как обрабатываются данные других типов: с помощью операторов. Класс string тесно связан с библиотекой STL.
Обзор STL
Несмотря на большой размер стандартной библиотеки шаблонов и порой пугающий синтаксис, в действительности ее средства довольно легко использовать, если понять, как она построена и из каких элементов состоит. Поэтому, прежде чем переходить к рассмотрению примеров, познакомимся с основными составляющими STL.
Ядро стандартной библиотеки шаблонов включает три основных элемента: контейнеры, алгоритмы и итераторы. Они работают совместно один с другим, предоставляя тем самым готовые решения различных задач программирования.
Контейнеры — это объекты, которые содержат другие объекты.
Каждый контейнерный класс определяет набор функций, которые можно применять к данному контейнеру. Например, контейнер списка включает функции, предназначенные для выполнения вставки, удаления и объединения элементов. А стек включает функции, которые позволяют помещать значения в стек и извлекать их из стека.
Алгоритмы обрабатывают содержимое контейнеров. Алгоритмы обрабатывают содержимое контейнеров. Их возможности включают средства инициализации, сортировки, поиска и преобразования содержимого контейнеров. Многие алгоритмы работают с заданным диапазоном элементов контейнера. Итераторы подобны указателям.
Итераторы — это объекты, которые в той или иной степени действуют подобно указателям. Они позволяют циклически опрашивать содержимое контейнера практически так же, как это делается с помощью указателя при циклическом опросе элементов массива. Существует пять типов итераторов.
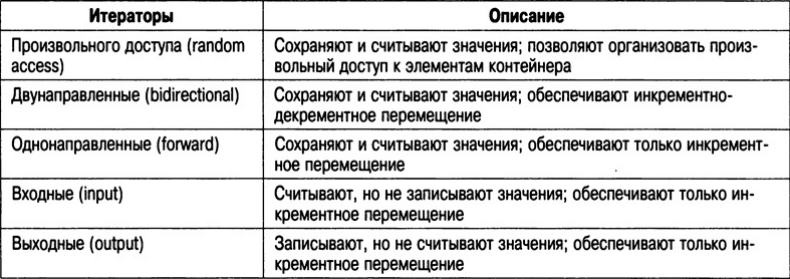
В общем случае итератор, который имеет большие возможности доступа, можно использовать вместо итератора с меньшими возможностями. Например, однонаправленным итератором можно заменить входной итератор.
Итераторы обрабатываются аналогично указателям. Их можно инкрементировать и декрементировать. К ним можно применять оператор разыменования адреса *. Итераторы объявляются с помощью типа iterator, определяемого различными контейнерами.
Библиотека STL поддерживает реверсивные итераторы, которые являются либо двунаправленными, либо итераторами произвольного доступа, позволяя перемещаться по последовательности в обратном направлении. Следовательно, если реверсивный итератор указывает на конец последовательности, то после инкрементирования он будет указывать на элемент, расположенный перед концом последовательности.
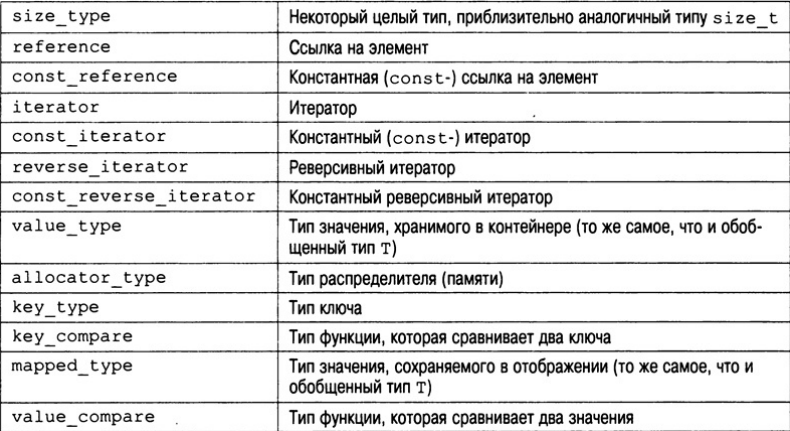
При ссылке на различные типы итераторов в описаниях шаблонов в этой книге будут использованы следующие термины.

STL опирается не только на контейнеры, алгоритмы и итераторы, но и на другие стандартные компоненты. Основными из них являются распределители памяти, предикаты и функции сравнения.
Распределитель памяти управляет выделением памяти для контейнера. Каждый контейнер имеет свой распределитель памяти (allocator). Распределители управляют выделением памяти для контейнера. Стандартный распределитель — это объект класса allocator, но при необходимости (в специализированных приложениях) можно определять собственные распределители. В большинстве случаев стандартного распределителя вполне достаточно.
Предикат возвращает в качестве результата значение ИСТИНА/ЛОЖЬ. Некоторые алгоритмы и контейнеры используют специальный тип функции, называемый предикатом (predicate). Существует два варианта предикатов: унарный и бинарный. Унарный предикат принимает один аргумент, а бинарный — два. Эти функции возвращают значения ИСТИНА/ЛОЖЬ, но точные условия, которые заставят их вернуть истинное или ложное значение, определяются программистом. В остальной части этой главы, когда потребуется унарная функция-предикат, на это будет указано с помощью типа UnPred. При необходимости использования бинарного предиката будет применяться тип BinPred. В бинарном предикате аргументы всегда расположены в порядке первый, второй относительно функции, которая вызывает этот предикат. Как для унарного, так и для бинарного предикатов аргументы должны содержать значения, тип которых совпадает с типом объектов, хранимых данным контейнером.
Функции сравнения сравнивают два элемента последовательности. Некоторые алгоритмы и классы используют специальный тип бинарного предиката, который сравнивает два элемента. Функции сравнения возвращают значение true, если их первый аргумент меньше второго. Функции сравнения идентифицируются с помощью типа Comp.
Помимо заголовков, требуемых различными классами STL, стандартная библиотека C++ включает заголовки <utility> и <functional>, которые обеспечивают поддержку STL. Например, в заголовке <utility> определяется шаблонный класс pair, который может хранить пару значений. Мы будем использовать класс pair ниже в этой главе.
Шаблоны в заголовке <functional> позволяют создавать объекты, которые определяют функцию operator(). Эти объекты называются объектами-функциями, и их во многих случаях можно использовать вместо указателей на функции. Существует несколько встроенных объектов-функций, объявленных в заголовке <functional>. Приведем здесь некоторые из них.

Возможно, наиболее широко используется объект-функция less, который определяет, при каких условиях один объект меньше другого. Объекты-функции можно использовать вместо реальных указателей на функции в алгоритмах STL, о которых пойдет речь ниже. Используя объекты-функции вместо указателей на функции, библиотека STL в некоторых случаях генерирует более эффективный программный код.
Материал этой главы не предусматривает использования объектов-функций, и мы не будем применять их напрямую.
Контейнерные классы
Как упоминалось выше, контейнеры представляют собой объекты STL, которые предназначены для хранения данных. Контейнеры, определяемые в STL, представлены в табл.В ней также указаны заголовки, которые необходимо включать в программу при использовании каждого контейнера. Но несмотря на то, что класс string также является контейнером, позволяющим хранить и обрабатывать символьные строки, он в эту таблицу не включен и рассматривается ниже в этой главе.

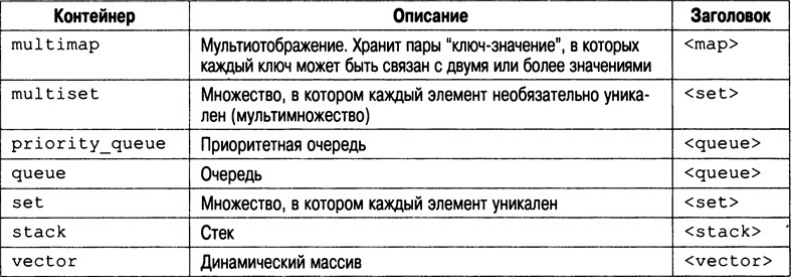
Поскольку имена типов в объявлениях шаблонных классов произвольны, контейнерные классы объявляют typedef-версии этих типов, что конкретизирует имена типов. Некоторые из наиболее популярных typedef-имен приведены ниже.
Поскольку в одной главе невозможно рассмотреть все контейнеры, в следующих разделах мы представим только три из них: vector, list и map. Если вы поймете, как работают эти три контейнера, у вас не будет проблем с использованием остальных.
Векторы
Векторы представляют собой динамические массивы. Одним из контейнеров самого широкого назначения является вектор. Класс vector поддерживает динамический массив, который при необходимости может увеличивать свой размер. Как вы знаете, в C++ размер массива фиксируется во время компиляции. И хотя это самый эффективный способ реализации массивов, он в то же время является и самым ограничивающим, поскольку размер массива нельзя изменять во время выполнения программы. Эта проблема решается с помощью вектора, который по мере необходимости обеспечивает выделение дополнительного объема памяти. Несмотря на то что вектор — это динамический массив, тем не менее, для доступа к его элементам можно использовать стандартное обозначение индексации массивов. Вот как выглядит шаблонная спецификация для класса vector:
template <class Т, class Allocator = allocator<T> > class vector
Здесь T— тип сохраняемых данных, а элемент Allocator означает распределитель памяти, который по умолчанию использует стандартный распределитель. Класс vector имеет следующие конструкторы.
explicit vector(const Allocator &a = Allocator());
explicit vector(size_type num, const T &val = T(), const
Allocator &a = Allocator());
vector(const vector<T, Allocator> &ob);
template <class InIter> vector(InIter start, InIter end, const
Allocator &a = Allocator());
Первая форма конструктора предназначена для создания пустого вектора. Вторая создает вектор, который содержит num элементов со значением val, причем значение val может быть установлено по умолчанию. Третья форма позволяет создать вектор, который содержит те же элементы, что и заданный вектор ob. Четвертая предназначена для создания вектора, который содержит элементы в диапазоне, заданном параметрами-итераторами start и end.
Ради достижения максимальной гибкости и переносимости любой объект, который предназначен для хранения в векторе, должен определяться конструктором по умолчанию. Кроме того, он должен определять операции "<" и "==" Некоторые компиляторы могут потребовать определения и других операторов сравнения. (В виду существования различных реализаций для получения точной информации о требованиях, предъявляемых вашим компилятором, следует обратиться к прилагаемой к нему документации.) Все встроенные типы автоматически удовлетворяют этим требованиям
Несмотря на то что приведенный выше синтаксис шаблона выглядит довольно "массивно", в объявлении вектора нет ничего сложного. Рассмотрим несколько примеров.
vector<int> iv; /* Создание вектора нулевой длины для хранения
int-значений. */
vector<char> cv(5); /* Создание 5-элементного вектора
для хранения char-значений. */
vector<char> cv(5, 'х'); /* Инициализация 5-элементного charвектора. */
vector<int> iv2(iv); /* Создание int-вектора на основе intвектора iv. */
Для класса vector определены следующие операторы сравнения:
==, <, <=, !=, > и >=
Для вектора также определен оператор индексации "[]", который позволяет получить доступ к элементам вектора с помощью стандартной записи с использованием индексов. Функции-члены, определенные в классе vector, перечислены в табл. Самыми важными из них являются size(), begin(), end(), push_back(), insert() и erase(). Очень полезна функция size(), которая возвращает текущий размер вектора, поскольку она позволяет определить размер вектора во время выполнения программы. Помните, что векторы при необходимости увеличивают свой размер, поэтому нужно иметь возможность определять его величину во время работы программы, а не только во время компиляции.
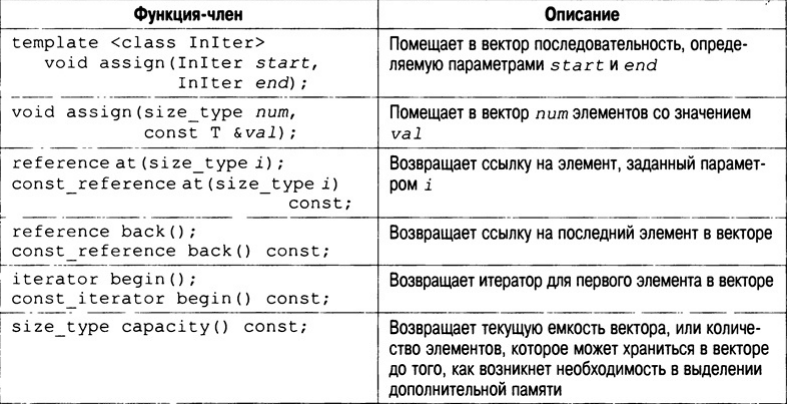

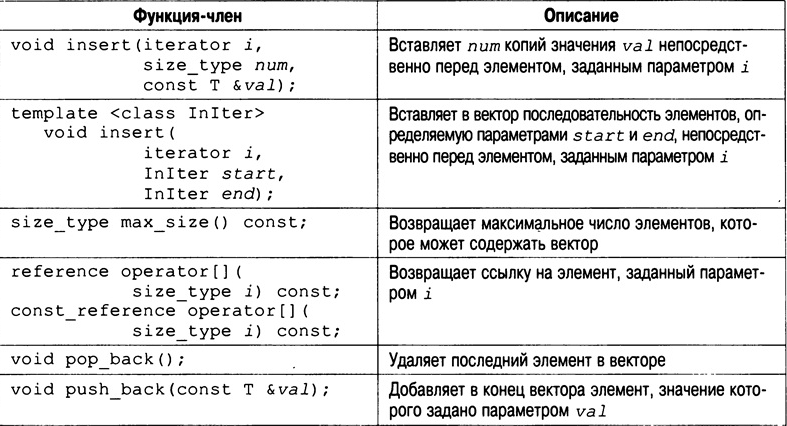
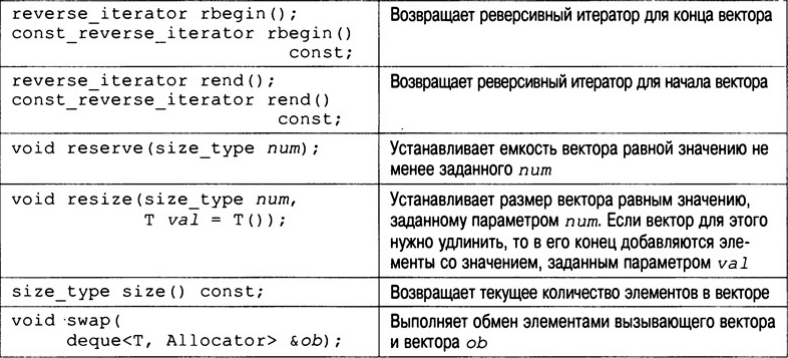
Функция begin() возвращает итератор, который указывает на начало вектора. Функция end() возвращает итератор, который указывает на конец вектора. Как уже разъяснялось, итераторы подобны указателям, и с помощью функций begin() и end() можно получить итераторы для начала и конца вектора соответственно.
Функция push_back() помещает заданное значение в конец вектора. При необходимости длина вектора увеличивается так, чтобы он мог принять новый элемент. С помощью функции insert() можно добавлять элементы в середину вектора. Кроме того, вектор можно инициализировать. В любом случае, если вектор содержит элементы, то для доступа к ним и их модификации можно использовать средство индексации массивов. А с помощью функции erase() можно удалять элементы из вектора. Рассмотрим короткий пример, который иллюстрирует базовое поведение вектора
// Демонстрация базового поведения вектора.
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<int> v; // создание вектора нулевой длины
unsigned int i;
// Отображаем исходный размер вектора v.
cout << "Размер = " << v.size() << endl;
/* Помещаем значения в конец вектора, и размер вектора будет
по необходимости у
cout << endl;
// Изменяем содержимое вектора.
for(i=0; i<v.size(); i++) v[i] = v[i] + v[i];
// Отображаем содержимое вектора.
cout << "Содержимое удвоено:\n";
for(i=0; i<v.size(); i++) cout << v[i] << " ";
cout << endl;
return 0;
}
Результаты выполнения этой программы таковы.
Размер = 0
Текущее содержимое:
Новый размер = 10
0 1 2 3 4 5 6 7 8 9
Новый размер = 20
Текущее содержимое:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Содержимое удвоено:
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38
Рассмотрим внимательно код этой программы. В функции main() создается вектор v для хранения int-элементов. Поскольку при его создании не было предусмотрено никакой инициализации, вектор v получился пустым, а его емкость равна нулю. Другими словами, мы создали вектор нулевой длины. Это подтверждается вызовом функции-члена size(). Затем, используя функцию-член push_back(), в конец этого вектора мы помещаем 10 элементов, что заставляет вектор увеличиться в размере, чтобы разместить новые элементы. Теперь размер вектора стал равным 10. Обратите внимание на то, что для отображения содержимого вектора v используется стандартная запись индексации массивов. После этого в вектор добавляются еще 10 элементов, и вектор v автоматически увеличивается в размере, чтобы и их принять на хранение. Наконец, используя опять-таки стандартную запись индексации массивов, мы изменяем значения элементов вектора v.
Обратите также внимание на то, что для управления циклами, используемыми для отображения содержимого вектора v и его модификации, в качестве признака их завершения применяется значение размера вектора, получаемое с помощью функции v.size(). Одно из преимуществ векторов перед массивами состоит в том, что у нас есть возможность узнать текущий размер вектора, что в определенных ситуациях является очень полезным средством.
Доступ к вектору с помощью итератора
Как вы знаете, массивы и указатели в C++ тесно связаны между собой. К элементам массива можно получить доступ как с помощью индекса, так и с помощью указателя. В библиотеке STL аналогичная связь существует между векторами и итераторами. Это значит, что к членам вектора можно обращаться как с помощью индекса, так и с помощью итератора. Эта возможность демонстрируется в следующей программе.
// Доступ к вектору с помощью итератора.
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<char> v; // создание массива нулевой длины
int i;
// Помещаем значения в вектор.
for(i=0; i<10; i++) v.push_back('A' + i);
/* Получаем доступ к содержимому вектора с помощью индекса. */
for(i=0; i<10; i++) cout << v[i] << " ";
cout << endl;
/* Получаем доступ к содержимому вектора с помощью итератора.
*/
vector<char>:: iterator р = v.begin();
while(p != v.end()) {
cout << *p << " ";
p++;
}
return 0;
}
Вот как выглядят результаты выполнения этой программы.
A B C D E F G H I J
A B C D E F G H I J
В этой программе сначала создается вектор нулевой длины. Затем с помощью функции push_back() в конец вектора помещаются символы, в результате чего размер вектора соответствующим образом увеличивается.
Обратите внимание на то, как объявляется итератор р. Тип этого итератора определяется контейнерными классами. Поэтому для получения итератора для конкретного контейнера используйте объявление, аналогичное показанному в этом примере: просто укажите для данного итератора имя контейнера. В нашей программе итератор p инициализируется таким образом, чтобы он указывал на начало вектора (с помощью функции-члена begin()). Итератор, который возвращает эта функция, можно затем использовать для поэлементного доступа к вектору, инкрементируя его соответствующим образом. Этот процесс аналогичен тому, как можно использовать указатель для доступа к элементам массива. Чтобы определить, когда будет достигнут конец вектора, используется функция-член end(). Эта функция возвращает итератор, установленный за последним элементом вектора. Поэтому, если значение р равно v.end(), значит, конец вектора достигнут.
Вставка и удаление элементов из вектора
Помимо занесения новых элементов в конец вектора, у нас есть возможность вставлять элементы в середину вектора, используя функцию insert(). Удалять элементы можно с помощью функции erase(). Использование функций insert() и erase() демонстрируется в следующей программе.
// Демонстрация вставки элементов в вектор и удаления их из
него.
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<char> v;
unsigned int i;
for(i=0; i<10; i++) v.push_back('A' + i);
// Отображаем исходное содержимое вектора.
cout << "Размер = " << v.size() << endl;
cout << "Исходное содержимое вектора:\n";
for(i=0; i<v.size(); i++) cout << v[i] << " ";
cout << endl << endl;
vector<char>:: iterator p = v.begin();
p += 2; // указатель на 3-й элемент вектора
// Вставляем 10 символов 'X' в вектор v.
v.insert(p, 10, 'X');
/* Отображаем содержимое вектора после вставки символов. */
cout << "Размер вектора после вставки = " << v.size()<< endl;
cout << "Содержимое вектора после вставки:\n";
for(i=0; i<v.size(); i++) cout << v[i] << " ";
cout << endl << endl;
// Удаление вставленных элементов.
p = v.begin();
p += 2; // указатель на 3-й элемент вектора
v.erase(р, р+10); // Удаляем 10 элементов подряд.
/* Отображаем содержимое вектора после удаления символов. */
cout << "Размер вектора после удаления символов = "<< v.size()
<< endl;
cout << "Содержимое вектора после удаления символов:\n";
for(i=0; i<v.size(); i++) cout << v[i] << " ";
cout << endl;
return 0;
}
При выполнении эта программа генерирует следующие результаты.
Размер = 10
Исходное содержимое вектора:
A B C D E F G H I J
Размер вектора после вставки = 20
Содержимое вектора после вставки:
A B X X X X X X X X X X C D E F G H I J
Размер вектора после удаления символов = 10
Содержимое вектора после удаления символов:
A B C D E F G H I J
Сохранение в векторе объектов класса
В предыдущих примерах векторы служили для хранения значений только встроенных типов, но этим их возможности не ограничиваются. В вектор можно помещать объекты любого типа, включая объекты классов, создаваемых программистом. Рассмотрим пример, в котором вектор используется для хранения объектов класса three_d. Обратите внимание на то, что в этом классе определяются конструктор по умолчанию и перегруженные версии операторов "<" и "==". Имейте в виду, что, возможно, вам придется определить и другие операторы сравнения. Это зависит от того, как используемый вами компилятор реализует библиотеку STL.
// Хранение в векторе объектов класса.
#include <iostream>
#include <vector>
using namespace std;
class three_d {
int x, y, z;
public:
three_d() { x = у = z = 0; }
three_d(int a, int b, int с) { x = a; у = b; z = c; }
three_d &operator+(int a) {
x += a;
у += a;
z += a;
return *this;
}
friend ostream &operator<<(ostream &stream, three_d obj);
friend bool operator<(three_d a, three_d b);
friend bool operator==(three_d a, three_d b);
};
/* Отображаем координаты X, Y, Z с помощью оператора вывода для
класса three_d. */
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << ", ";
stream << obj.у << ", ";
stream << obj.z << "\n";
return stream;
}
bool operator<(three_d a, three_d b)
{
return (a.x + a.у + a.z) < (b.x + b.y + b.z);
}
bool operator==(three_d a, three_d b)
{
return (a.x + a.у + a.z) == (b.x + b.y + b.z);
}
int main()
{
vector<three_d> v;
unsigned int i;
// Добавляем в вектор объекты.
for(i=0; i<10; i++)
v.push_back(three_d(i, i+2, i-3));
// Отображаем содержимое вектора.
for(i=0; i<v.size(); i++)
cout << v[i];
cout << endl;
// Модифицируем объекты в векторе.
for(i=0; i<v.size(); i++) v [i] = v[i] + 10;
// Отображаем содержимое модифицированного вектора.
for(i=0; i<v.size(); i++) cout << v[i];
return 0;
}
Эта программа генерирует такие результаты.
0, 2, -3
1, 3, -2
2, 4, -1
3, 5, 0
5, 7, 2
6, 8, 3
7, 9, 4
8, 10, 5
9, 11, 6
10, 12, 7
11, 13, 8
12, 14, 9
13, 15, 10
14, 16, 11
15, 17, 12
16, 18, 13
17, 19, 14
18, 20, 15
19, 21, 16
Векторы обеспечивают безопасность хранения элементов, обнаруживая при этом чрезвычайную мощь и гибкость их обработки, но уступают массивам в эффективности использования. Поэтому для большинства задач программирования чаще отдается предпочтение обычным массивам. Однако возможны ситуации, когда уникальные особенности векторов оказываются важнее затрат системных ресурсов, связанных с их использованием.
О пользе итераторов
Частично сила библиотеки STL обусловлена тем, что многие ее функции используют итераторы. Этот факт позволяет выполнять операции с двумя контейнерами одновременно. Рассмотрим, например, такой формат векторной функции insert().
template <class InIter>
void insert(iterator i, InIter start, InIter end);
Эта функция вставляет исходную последовательность, определенную параметрами start и end, в приемную последовательность, начиная с позиции i. При этом нет никаких требований, чтобы итератор i относился к тому же вектору, с которым связаны итераторы start и end. Таким образом, используя эту версию функции insert(), можно один вектор вставить в другой. Рассмотрим пример.
// Вставляем один вектор в другой.
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector<char> v, v2;
unsigned int i;
for(i=0; i<10; i++) v.push_back('A' + i);
// Отображаем исходное содержимое вектора.
cout << "Исходное содержимое вектора:\n";
for(i=0; i<v.size(); i++)
cout << v[i] << " ";
cout << endl << endl;
// Инициализируем второй вектор.
char str[] = "-STL — это сила!-";
for(i=0; str[i]; i++) v2 .push_back (str [i]);
/* Получаем итераторы для середины вектора v, а также начала и
конца вектора v2. */
vector<char>::iterator р = v.begin()+5;
<char>::iterator p2start = v2.begin();
vector<char>::iterator p2end = v2.end();
// Вставляем вектор v2 в вектор v.
v.insert(p, p2start, p2end);
// Отображаем результат вставки.
cout << "Содержимое вектора v после вставки:\n";
for(i=0; i<v.size(); i++) cout << v[i] << " ";
return 0;
}
При выполнении эта программа генерирует следующие результаты.
Исходное содержимое вектора:
A B C D E F G H I J
Содержимое вектора v после вставки:
A B C D E - S T L -- это cилa! - F G H I J
Как видите, содержимое вектора v2 вставлено в середину вектора v. По мере дальнейшего изучения возможностей, предоставляемых STL, вы узнаете, что итераторы являются связующими средствами, которые делают библиотеку единым целым. Они позволяют работать с двумя (и больше) объектами STL одновременно, но особенно полезны при использовании алгоритмов, описанных ниже в этой главе.
Списки
Список — это контейнер с двунаправленным последовательным доступом к его элементам
Класс list поддерживает функционирование двунаправленного линейного списка. В отличие от вектора, в котором реализована поддержка произвольного доступа, список позволяет получать к своим элементам только последовательный доступ. Двунаправленность списка означает, что доступ к его элементам возможен в двух направлениях: от начала к концу и от конца к началу. Шаблонная спецификация класса list выглядит следующим образом.
template <class Т, class Allocator = allocator<T>> class list
Здесь T — тип данных, сохраняемых в списке, а элемент Allocator означает распределитель памяти, который по умолчанию использует стандартный распределитель. В классе list определены следующие конструкторы.
explicit list(const Allocator &а = Allocator() );
explicit list(size_type num, const T &val = T(), const Allocator
&a = Allocator());
list(const list<T, Allocator> &ob);
template <class InIter>list(InIter start, InIter end, const
Allocator &a = Allocator());
Конструктор, представленный в первой форме, создает пустой список. Вторая форма предназначена для создания списка, который содержит num элементов со значением val. Третья создает список, который содержит те же элементы, что и объект ob. Четвертая создает список, который содержит элементы в диапазоне, заданном параметрами start и end.Для класса list определены следующие операторы сравнения:
==, <, <=, !=, > и >=
Функции-члены, определенные в классе list, перечислены в табл. В конец списка, как и в конец вектора, элементы можно помещать с помощью функции push_back(), но с помощью функции push_front() можно помещать элементы в начало списка. Элемент можно также вставить и в середину списка, для этого используется функция insert(). Один список можно поместить в другой, используя функцию splice(). А с помощью функции merge() два списка можно объединить и упорядочить результат.
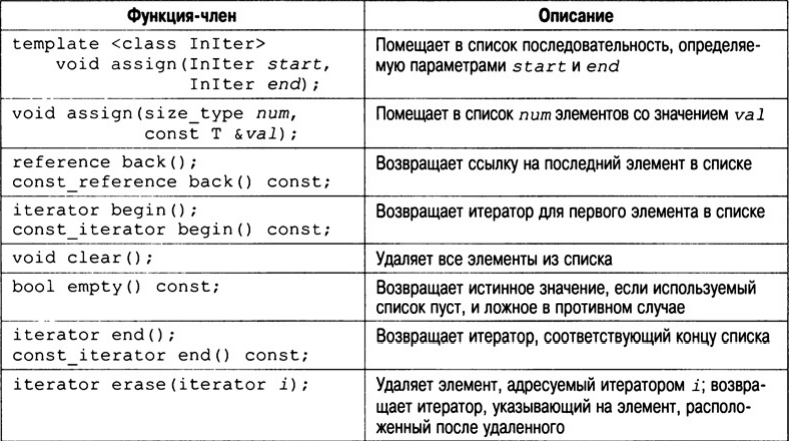
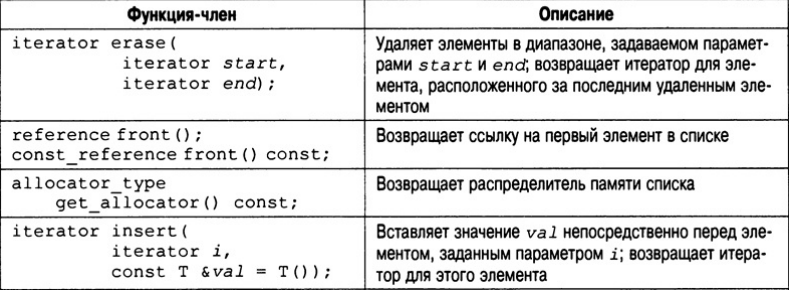
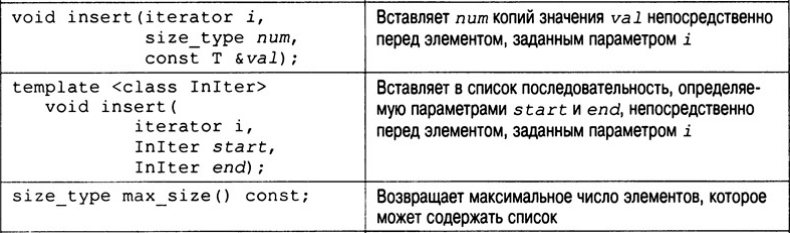

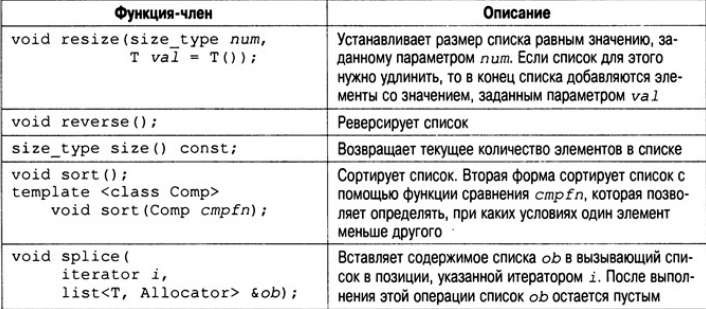
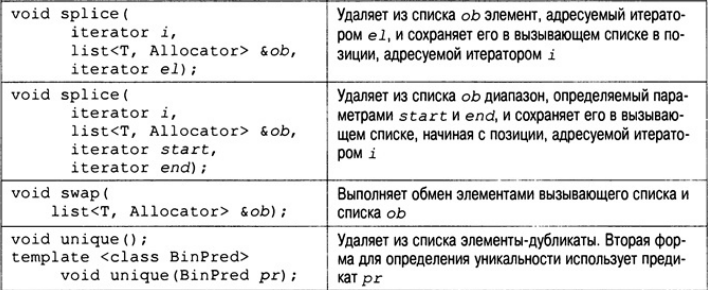
Чтобы достичь максимальной гибкости и переносимости для любого объекта, который подлежит хранению в списке, следует определить конструктор по умолчанию и оператор " <" (и желательно другие операторы сравнения). Более точные требования к объекту (как к потенциальному элементу списка) необходимо согласовывать в соответствии с документацией на используемый вами компилятор. Рассмотрим простой пример списка.
// Базовые операции, определенные для списка.
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<char> lst; // создание пустого списка
int i;
for(i=0; i<10; i++) lst.push_back('A'+i);
cout << "Размер = " << lst.size() << endl;
cout << "Содержимое : ";
list<char>::iterator p = lst.begin();
while(p != lst.end()) {
cout << *p;
p++;
}
return 0;
}
Результаты выполнения этой программы таковы:
Размер = 10
Содержимое : ABCDEFGHIJ
При выполнении эта программа создает список символов. Сначала создается пустой объект списка. Затем в него помещается десять букв (от А до J). Заполнение списка реализуется путем использования функции push_back(), которая помещает каждое новое значение в конец существующего списка. После этого отображается размер списка и его содержимое. Содержимое списка выводится на экран в результате выполнения следующего кода.
list<char>::iterator р = lst.begin();
while(p != lst.end()) {
cout << *p;
p++;
}
Здесь итератор p инициализируется таким образом, чтобы он указывал на начало списка. При выполнении очередного прохода цикла итератор р инкрементируется, чтобы указывать на следующий элемент списка. Этот цикл завершается, когда итератор р указывает на конец списка. Применение подобных циклов — обычная практика при использовании библиотеки STL. Например, аналогичный цикл мы применили для отображения содержимого вектора в предыдущем разделе.
Поскольку списки являются двунаправленными, заполнение их элементами можно производить с обоих концов. Например, при выполнении следующей программы создается два списка, причем элементы одного из них расположены в порядке, обратном по отношению к другому.
/* Элементы можно помещать в список как с начала, так и с конца.
*/
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<char> lst;
list<char> revlst;
int i;
for(i=0; i<10; i++ ) lst.push_back('A'+i);
cout << "Размер списка lst = " << lst.size() << endl;
cout << "Исходное содержимое списка: ";
list<char>::iterator p;
/* Удаляем элементы из списка lst и помещаем их в список
revlst в обратном порядке. */
while(!lst.empty()) {
р = lst.begin();
cout << *р;
revlst.push_front(*р);
lst.pop_front();
}
cout << endl << endl;
cout << "Размер списка revlst = ";
cout << revlst.size() << endl;
cout << "Реверсированное содержимое списка: ";
p = revlst.begin();
while(p != revlst.end()) {
cout << *p;
p++;
}
return 0;
}
Эта программа генерирует такие результаты.
Размер списка lst = 10
Исходное содержимое списка: ABCDEFGHIJ
Размер списка revlst = 10
Реверсированное содержимое списка: JIHGFEDCBA
В этой программе список реверсируется путем удаления элементов с начала списка lst и
занесения их в начало списка revlst.
Сортировка списка
Список можно отсортировать с помощью функции-члена sort(). При выполнении следующей программы создается список случайно выбранных целых чисел, который затем упорядочивается по возрастанию.
// Сортировка списка.
#include <iostream>
#include <list>
#include <cstdlib>
using namespace std;
int main()
{
list<int> lst;
int i;
// Создание списка случайно выбранных целых чисел.
for(i=0; i<10; i++ )lst.push_back(rand() );
cout << "Исходное содержимое списка:\n";
list<int>::iterator p = lst.begin();
while(p != lst.end()) {
cout << *p << " ";
p++;
}
cout << endl << endl;
// Сортировка списка.
lst.sort();
cout << "Отсортированное содержимое списка:\n";
p = lst.begin();
while(p != lst.end()) {
cout << *p << " ";
p++;
}
return 0;
}
Вот как может выглядеть один из возможных вариантов выполнения этой программы.
Исходное содержимое списка:
41 18467 6334 26500 19169 15724 11478 29358 26962 24464
Отсортированное содержимое списка:
41 6334 11478 15724 18467 19169 24464 26500 26962 29358
Объединение одного списка с другим
Один упорядоченный список можно объединить с другим. В результате мы получим упорядоченный список, который включает содержимое двух исходных списков. Новый список остается в вызывающем списке, а второй список становится пустым. В следующем примере выполняется слияние двух списков. Первый список содержит буквы ACEGI, а второй— буквы BDFHJ. Эти списки затем объединяются, в результате чего образуется упорядоченная последовательность букв ABCDEFGHIJ.
// Слияние двух списков.
#include <iostream>
#include <list>
using namespace std;
int main()
{
list<char> lst1, lst2;
int i;
for(i=0; i<10; i+=2) lst1.push_back('A'+i);
for(i=1; i<11; i+=2) lst2.push_back('A'+i);
cout << "Содержимое списка lst1: ";
list<char>::iterator p = lst1.begin();
while(p != lst1.end()) {
cout << *p;
p++;
}
cout << endl << endl;
cout << "Содержимое списка lst2: ";
р = lst2.begin();
while(p != lst2.end()) {
cout << *p;
p++;
}
cout << endl << endl;
// Теперь сливаем эти два списка.
lst1.merge(lst2);
if(lst2.empty())
cout << "Список lst2 теперь пуст.\n";
cout << "Содержимое списка lst1 после объединения:\n";
р = lst1.begin();
while(p != lst1.end()) {
cout << *p;
p++;
}
return 0;
}
Результаты выполнения этой программы таковы.
Содержимое списка lst1: ACEGI
Содержимое списка lst2: BDFHJ
Список lst2 теперь пуст.
Содержимое списка lst1 после объединения:
ABCDEFGHIJ
Хранение в списке объектов класса
Рассмотрим пример, в котором список используется для хранения объектов типа myclass. Обратите внимание на то, что для объектов типа myclass перегружены операторы " <", ">", "!=" и "==". (Для некоторых компиляторов может оказаться излишним определение всех этих операторов или же придется добавить некоторые другие.) В библиотеке STL эти функции используются для определения упорядочения и равенства объектов в контейнере. Несмотря на то что список не является упорядоченным контейнером, необходимо иметь средство сравнения элементов, которое применяется при их поиске, сортировке или объединении.
// Хранение в списке объектов класса.
#include <iostream>
#include <list>
#include <cstring>
using namespace std;
class myclass {
int a, b;
int sum;
public:
myclass() { a = b = 0; }
myclass(int i, int j) {
a = i;
b = j;
sum = a + b;
}
int getsum() { return sum; }
friend bool operator<(const myclass &o1, const myclass &o2);
friend bool operator>(const myclass &o1, const myclass &o2);
friend bool operator==(const myclass &o1, const myclass
&o2);
friend bool operator!=(const myclass &o1, const myclass
&o2);
};
bool operator<(const myclass &o1, const myclass &o2)
{
return o1.sum < o2.sum;
}
bool operator>(const myclass &o1, const myclass &o2)
{
return o1.sum > o2.sum;
}
bool operator==(const myclass &o1, const myclass &o2)
{
return o1.sum == o2.sum;
}
bool operator!=(const myclass &o1, const myclass &o2)
{
return o1.sum != o2.sum;
}
int main()
{
int i;
// Создание первого списка.
list<myclass> lst1;
for(i=0; i < 10; i++) lst1.push_back(myclass(i, i));
cout << "Первый список: ";
list<myclass>::iterator p = lst1.begin();
while(p != lst1.end()) {
cout << p->getsum() << " ";
p++;
}
cout << endl;
// Создание второго списка.
list<myclass> lst2;
for(i=0; i<10; i++) lst2.push_back(myclass(i*2, i*3));
cout << "Второй список: ";
p = lst2.begin();
while(p != lst2.end()) {
cout << p->getsum() << " ";
p++;
}
cout << endl;
// Теперь объединяем списки lst1 и lst2.
lst1.merge(lst2);
// Отображаем объединенный список.
cout << "Объединенный список: ";
р = lst1.begin();
while(p != lst1.end()) {
cout << p->getsum() << " ";
p++;
}
return 0;
}
Эта программа создает два списка объектов типа myclass и отображает их содержимое.
Затем выполняется объединение этих двух списков с последующим отображением нового
содержимого результирующего списка. Итак, программа генерирует такие результаты.
Первый список: 0 2 4 6 8 10 12 14 16 18
Второй список: 0 5 10 15 20 25 30 35 40 45
Объединенный список: 0 0 2 4 5 6 8 10 10 12 14 15 16 18 20 25 30
35 40 45
Отображения
Отображение — это ассоциативный контейнер. Класс map поддерживает ассоциативный контейнер, в котором уникальным ключам соответствуют определенные значения. По сути, ключ — это просто имя, которое присвоено некоторому значению. После того как значение сохранено в контейнере, к нему можно получить доступ, используя его ключ. Таким образом, в самом широком смысле отображение — это список пар "ключ-значение". Если нам известен ключ, мы можем легко найти значение. Например, мы могли бы определить отображение, в котором в качестве ключа используется имя человека, а в качестве значения — его телефонный номер. Ассоциативные контейнеры становятся все более популярными в программировании. Как упоминалось выше, отображение может хранить только уникальные ключи. Ключидубликаты не разрешены. Чтобы создать отображение, которое бы позволяло хранить неуникапьные ключи, используйте класс multimap. Контейнер map имеет следующую шаблонную спецификацию.
template <class Key, class T, class Comp = less<Key>, class
Allocator =allocator<pair<const Key, T> > >class map
Здесь Key— тип данных ключей, T— тип сохраняемых (отображаемых) значений, а Comp
— функция, которая сравнивает два ключа. По умолчанию в качестве функции сравнения
используется стандартная функция-объект less. Элемент Allocator означает распределитель
памяти, который по умолчанию использует стандартный распределитель allocator.
Класс map имеет следующие конструкторы.
explicit map(const Comp &cmpfn = Comp(), const Allocator &a =
Allocator());
map(const map<Key, T, Comp, Allocator> &ob);
template <class InIter> map(InIter start, InIter end, const Comp
&cmpfn = Comp(), const Allocator &a = Allocator());
Первая форма конструктора создает пустое отображение. Вторая предназначена для
создания отображения, которое содержит те же элементы, что и отображение ob. Третья
создает отображение, которое содержит элементы в диапазоне, заданном итераторами start
и end. Функция, заданная параметром cmpfn (если она задана), определяет характер
упорядочения отображения.
В общем случае любой объект, используемый в качестве ключа, должен определять
конструктор по умолчанию и перегружать оператор "<" (а также другие необходимые
операторы сравнения). Эти требования для разных компиляторов различны.
Для класса map определены следующие операторы сравнения:
==, <, <=, !=, > и >=
Функции-члены, определенные для класса map, представлены в табл. 21.4. В их
описании под элементом key_type понимается тип ключа, а под элементом value_type —
значение выражения pair<Key, Т>.
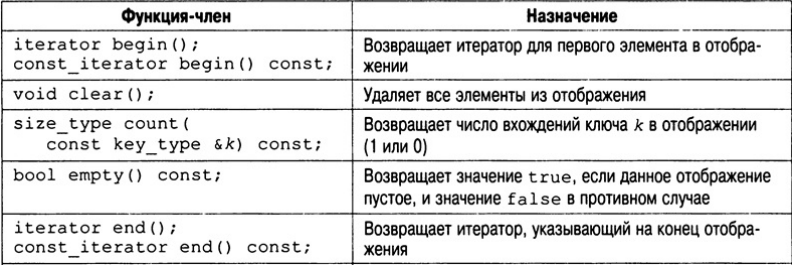

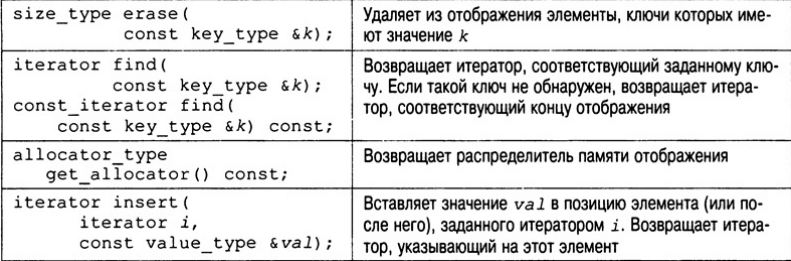

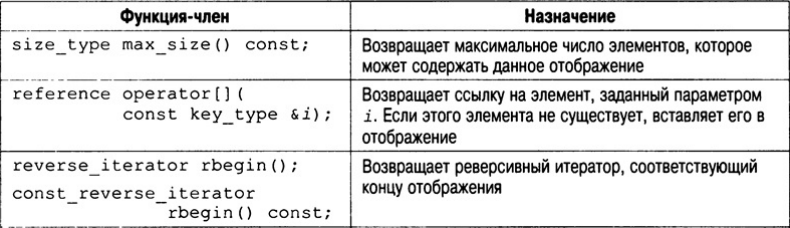
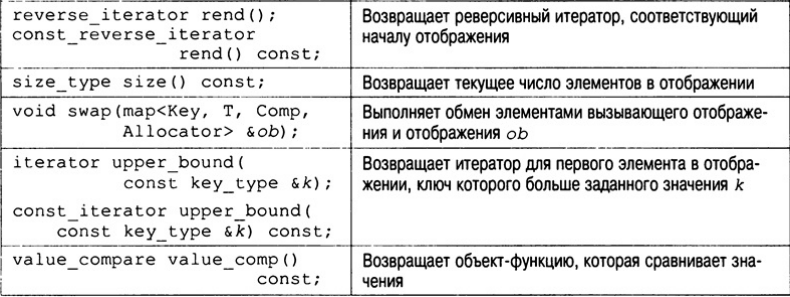
Пары "ключ-значение" хранятся в отображении как объекты класса pair, который имеет следующую шаблонную спецификацию.
template <class Ktype, class Vtype>
struct pair {
typedef Ktype first_type; // тип ключа
typedef Vtype second_type; // тип значения
Ktype first; // содержит ключ
Vtype second; // содержит значение
// Конструкторы
pair();
pair (const Ktype &k, const Vtype &v);
template<class A, class B> pair(const<A, B> &ob);
}
Как отмечено в комментариях, член first содержит ключ, а член second — значение, соответствующее этому ключу.
Создать пару "ключ-значение" можно либо с помощью конструкторов класса pair, либо путем вызова функции make_pair(), которая создает парный объект на основе типов данных, используемых в качестве параметров. Функция make_pair() — это обобщенная функция, прототип которой имеет следующий вид.
template <class Ktype, class Vtype>
pair<Ktype, Vtype> make_pair(const Ktype &k, const Vtype &v);
Как видите, функция make_pair() возвращает парный объект, состоящий из значений, типы которых заданы параметрами Ktype и Vtype. Преимущество использования функции make_pair() состоит в том, что типы объектов, объединяемых в пару, определяются автоматически компилятором, а не явно задаются программистом.
Возможности использования отображения демонстрируется в следующей программе. В данном случае в отображении сохраняется 10 пар "ключ-значение". Ключом служит символ, а значением — целое число. Пары "ключ-значение" хранятся следующим образом:
А 0
В 1
С 2
и т.д. После сохранения пар в отображении пользователю предлагается ввести ключ (т.е. букву из диапазона А-J), после чего выводится значение, связанное с этим ключом.
// Демонстрация использования простого отображения.
#include <iostream>
#include <map>
using namespace std;
int main()
{
map<char, int> m;
int i;
// Помещаем пары в отображение.
fоr(i = 0; i <10; i++) {
m.insert(pair<char, int>('A'+i, i));
}
char ch;
cout << "Введите ключ: ";
cin >> ch;
map<char, int>::iterator p;
// Находим значение по заданному ключу.
р = m.find(ch);
if(р != m.end())
cout << p->second;
else cout << "Такого ключа в отображении нет.\n";
return 0;
}
Обратите внимание на использование шаблонного класса pair для построения пар "ключ-значение". Типы данных, задаваемые pair-выражением, должны соответствовать типам отображения, в которое вставляются эти пары.
После инициализации отображения ключами и значениями можно выполнять поиск значения по заданному ключу, используя функцию find(). Эта функция возвращает итератор, который указывает на нужный элемент или на конец отображения, если заданный ключ не был найден. При обнаружении совпадения значение, связанное с ключом, можно найти в члене second парного объекта типа pair.
В предыдущем примере пары "ключ-значение" создавались явным образом с помощью шаблона pair<char, int>. И хотя в этом нет ничего неправильного, зачастую проще использовать с этой целью функцию make_pair(), которая создает pair-объект на основе типов данных, используемых в качестве параметров. Например, эта строка кода также позволит вставить в отображение m пары "ключ-значение" (при использовании предыдущей программы):
m.insert(make_pair((char) ('А'+i), i));
Здесь, как видите, выполняется операция приведения к типу char, которая необходима для переопределения автоматического преобразования в тип int результата сложения значения i с символом 'А'.
Хранение в отображении объектов класса
Подобно всем другим контейнерам, отображение можно использовать для хранения объектов создаваемых вами типов. Например, следующая программа создает простой словарь на основе отображения слов с их значениями. Но сначала она создает два класса word и meaning. Поскольку отображение поддерживает отсортированный список ключей, программа также определяет для объектов типа word оператор "<". В общем случае оператор "<" следует определять для любых классов, которые вы собираетесь использовать в качестве ключей. (Некоторые компиляторы могут потребовать определения и других операторов сравнения.)
// Использование отображения для создания словаря.
#include <iostream>
#include <map>
#include <cstring>
using namespace std;
class word {
char str[20];
public:
word() { strcpy(str, ""); }
word(char *s) { strcpy(str, s); }
char *get() { return str; }
};
bool operator<(word a, word b)
{
return strcmp(a.get(), b.get()) < 0;
}
class meaning {
char str[80];
public:
meaning() { strcmp(str, " ");}
meaning(char *s) { strcpy(str, s); }
char *get() { return str; }
};
int main()
{
map<word, meaning> dictionary;
/* Помещаем в отображение объекты классов word и meaning. */
dictionary.insert( pair<word, meaning> (word("дом"),
meaning("Место проживания.")));
dictionary.insert( pair<word, meaning> (word("клавиатура"),
meaning("Устройство ввода данных.")));
dictionary.insert( pair<word, meaning>
(word("программирование"), meaning("Процесс создания
программы.")));
dictionary.insert( pair<word, meaning> (word("STL"),
meaning("Standard Template Library")));
// По заданному слову находим его значение.
char str[80];
cout << "Введите слово: ";
cin >> str;
map<word, meaning>::iterator р;
р = dictionary.find(word(str));
if(p != dictionary.end())
cout << "Определение: " << p->second.get();
else cout << "Такого слова в словаре нет.\n";
return 0;
}
Вот один из возможных вариантов выполнения этой программы.
Введите слово: дом
Определение: Место проживания.
В этой программе каждый элемент отображения представляет собой символьный массив, который содержит строку с завершающим нулем. Ниже в этой главе мы рассмотрим более простой вариант построения этой программы, в которой использован стандартный тип string.
Алгоритмы
Алгоритмы обрабатывают данные, содержащиеся в контейнерах. Несмотря на то что каждый контейнер обеспечивает поддержку собственных базовых операций, стандартные алгоритмы позволяют выполнять более расширенные или более сложные действия. Они также позволяют работать с двумя различными типами контейнеров одновременно. Для получения доступа к алгоритмам библиотеки STL необходимо включить в программу заголовок <algorithm>.
В библиотеке STL определено множество алгоритмов, которые описаны в табл. Все эти алгоритмы представляют собой шаблонные функции. Это означает, что их можно применять к контейнеру любого типа.
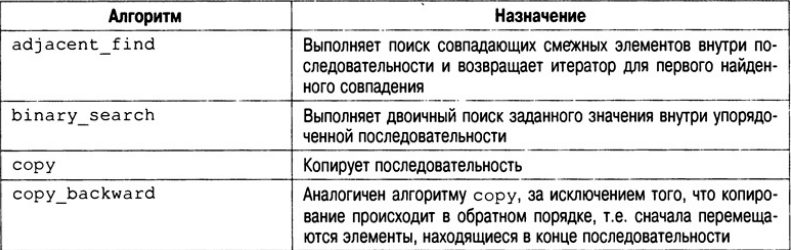
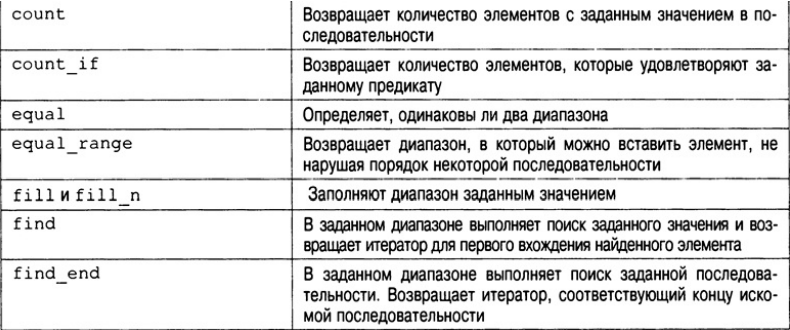

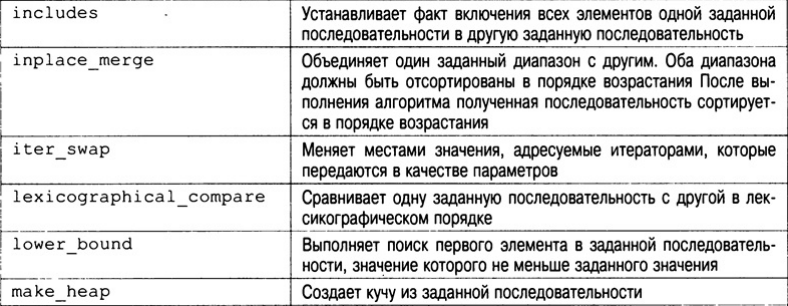
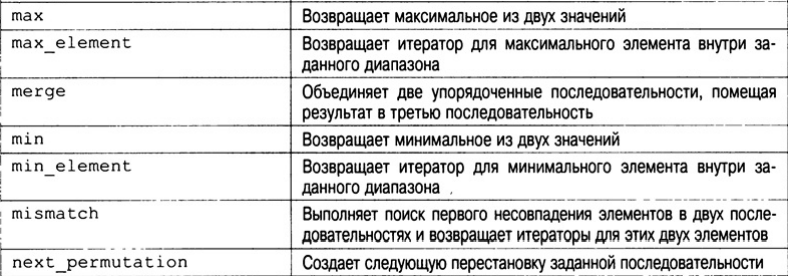

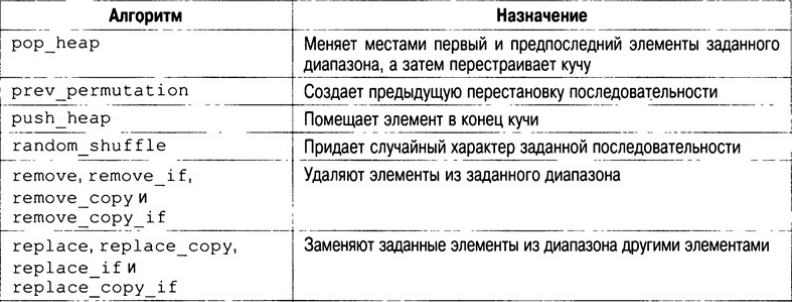
Подсчет элементов
Одна из самых популярных операций, которую можно выполнить для любой последовательности элементов, — подсчитать их количество. Для этого можно использовать один из алгоритмов: count() или count_if(). Общий формат этих алгоритмов имеет следующий вид.
template <class InIter, class T>
ptrdiff_t count(InIter start, InIter end, const T &val);
template <class InIter, class UnPred>
ptrdiff_t count_if(InIter start, InIter end, UnPred pfn);
Алгоритм count() возвращает количество элементов, равных значению val, в последовательности, границы которой заданы параметрами start и end. Алгоритм count_if(), действуя в последовательности, границы которой заданы параметрами start и end, возвращает количество элементов, для которых унарный предикат pfn возвращает значение true. Тип ptrdif _t определяется как некоторая разновидность целочисленного типа. Использование алгоритмов count() и count_if() демонстрируется в следующей программе.
/* Демонстрация использования алгоритмов count и count_if.
*/
#include <iostream>
#include <vector>
#include <algorithm>
#include <cctype>
using namespace std;
/* Это унарный предикат, который определяет, представляет ли
данный символ гласный звук.
*/
bool isvowel(char ch)
{
ch = tolower(ch);
if(ch=='a' || ch=='e' || ch=='и' || ch=='o' || ch=='у' ||
ch=='ы' || ch=='я' || ch=='ё' || ch=='ю' || ch=='э')
return true;
return false;
}
int main()
{
char str[] = "STL-программирование — это сила!";
vector<char> v;
unsigned int i;
for(i=0; str[i]; i++) v.push_back(str[i]);
cout << "Последовательность: ";
for(i=0; i<v.size(); i++) cout << v[i];
cout << endl;
int n;
n = count (v.begin(), v.end(), 'м');
cout << n << " символа м\n";
n = count_if(v.begin(), v.end(), isvowel);
cout << n << " символов представляют гласные звуки.\n";
return 0;
}
При выполнении эта программа генерирует такие результаты.
Последовательность: STL-программирование -- это сила!
2 символа м
11 символов представляют гласные звуки.
Программа начинается с создания вектора, который содержит строку "STLпрограммирование - это сила!". Затем используется алгоритм count() для подсчета количества букв 'м' в этом векторе. После этого вызывается алгоритм count_if(), который подсчитывает количество символов, представляющих гласные звуки с использованием в качестве предиката функции isvowel(). Обратите внимание на то, как закодирован этот предикат. Все унарные предикаты получают в качестве параметра объект, тип которого совпадает с типом элементов, хранимых в контейнере, для которого и создается этот предикат. Предикат должен возвращать значение ИСТИНА или ЛОЖЬ.
Удаление и замена элементов
Иногда полезно сгенерировать новую последовательность, которая будет состоять только из определенных элементов исходной последовательности. Одним из алгоритмов, который может справиться с этой задачей, является remove_copy(). Его общий формат выглядит так.
template <class ForIter, class OutIter, class T>
OutIter remove_copy(InIter start, InIter end, OutIter result,
const T &val);
Алгоритм remove_copy() копирует с извлечением из заданного диапазона элементы, которые равны значению val, и помещает результат в последовательность, адресуемую параметром result. Алгоритм возвращает итератор, указывающий на конец результата. Контейнер-приемник должен быть достаточно большим, чтобы принять результат. Чтобы в процессе копирования один элемент в последовательности заменить другим, используйте алгоритм replace_copy(). Его общий формат выглядит так.
template <class ForIter, class OutIter, class T>
OutIter replace_copy(InIter start, InIter end, OutIter result,
const T &old, Const T &new);
Алгоритм replace_copy() копирует элементы из заданного диапазона в последовательность, адресуемую параметром result. В процессе копирования происходит замена элементов, которые имеют значение old, элементами, имеющими значение new. Алгоритм помещает результат в последовательность, адресуемую параметром result, и возвращает итератор, указывающий на конец этой последовательности. Контейнерприемник должен быть достаточно большим, чтобы принять результат. В следующей программе демонстрируется использование алгоритмов remove_copy() и replace_copy(). При ее выполнении создается последовательность символов, из которой удаляются все буквы 'т'. Затем выполняется замена всех букв 'о' буквами 'Х'.
/* Демонстрация использования алгоритмов remove_copy и
replace_copy.
*/
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
char str[] = "Это очень простой тест.";
vector<char> v, v2(30);
unsigned int i;
for(i=0; str[i]; i++) v.push_back(str[i]);
// **** демонстрация алгоритма remove_copy ****
cout << "Входная последовательность: ";
for(i=0; i<v.size(); i++)
cout << v[i];
cout << endl;
// Удаляем все буквы 'т'.
remove_copy(v.begin(), v.end(), v2.begin(), 'Т');
cout << "После удаления букв 'т' : ";
for(i=0; v2[i]; i++)
cout << v2[i];
cout << endl << endl;
// **** Демонстрация алгоритма replace_copy ****
cout << "Входная последовательность: ";
for(i=0; i<v.size(); i++)
cout << v[i];
cout << endl;
// Заменяем буквы 'о' буквами 'Х'.
replace_copy(v.begin(), v.end(), v2.begin(), 'о', 'Х');
cout << "После замены букв 'o' буквами 'Х': ";
for(i=0; v2[i]; i++)
cout << v2[i];
cout << endl << endl;
return 0;
}
Результаты выполнения этой программы таковы.
Входная последовательность: Это очень простой тест.
После удаления букв 'т': Эо очень просой ес.
Входная последовательность: Это очень простой тест.
После замены букв 'о' буквами 'Х': ЭтХ Хчень прХстХй тест.
Реверсирование последовательности
В программах часто используется алгоритм reverse(), который в диапазоне, заданном параметрами start и end, меняет порядок следования элементов на противоположный. Его общий формат имеет следующий вид.
template <class BiIter>
void reverse(BiIter start, BiIter end);
В следующей программе демонстрируется использование этого алгоритма.
// Демонстрация использования алгоритма reverse.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main()
{
vector<int> v;
unsigned int i;
for(i=0; i<10; i++) v.push_back(i);
cout << "Исходная последовательность: ";
for(i=0; i<v.size(); i++)
cout << v[i] << " ";
cout << endl;
reverse (v.begin(), v.end());
cout << "Реверсированная последовательность: ";
for(i=0; i<v.size(); i++) cout << v[i] << " ";
return 0;
}
Результаты выполнения этой программы таковы.
Исходная последовательность: 0123456789
Реверсированная последовательность: 9876543210
Преобразование последовательности
Одним из самых интересных алгоритмов является transform(), поскольку он позволяет модифицировать каждый элемент в диапазоне в соответствии с заданной функцией. Алгоритм transform() используется в двух общих форматах.
template <class InIter, class OutIter, class Func>
OutIter transform(InIter start, InIter end, OutIter result, Func
unaryfunc);
template <class InIter1, class InIter2, class OutIter, class
Func>
OutIter transform(InIter1 start1, InIter1 end1, InIter2 start2,
OutIter result, Func binaryfunc);
Алгоритм transform() применяет функцию к диапазону элементов и сохраняет результат в последовательности, заданной параметром result. В первой форме диапазон задается параметрами start и end. Применяемая для преобразования функция задается параметром unaryfunc. Она принимает значение элемента в качестве параметра и должна возвратить преобразованное значение. Во второй форме алгоритма преобразование выполняется с использованием бинарной функции, которая принимает в качестве первого параметра значение предназначенного для преобразования элемента из последовательности, а в качестве второго параметра — элемент из второй последовательности. Обе версии возвращают итератор, указывающий на конец результирующей последовательности.
В следующей программе используется простая функция преобразования xform(), которая возводит в квадрат каждый элемент списка. Обратите внимание на то, что результирующая последовательность сохраняется в том же списке, который содержал исходную последовательность.
// Пример использования алгоритма transform.
#include <iostream>
#include <list>
#include <algorithm>
using namespace std;
// Простая функция преобразования.
int xform(int i) {
return i * i; // квадрат исходного значения
}
int main()
{
list<int> x1;
int i;
// Помещаем значения в список.
for(i=0; i<10; i++) x1.push_back(i);
cout << "Исходный список x1: ";
list<int>:: iterator p = x1.begin();
while(p != x1.end()) {
cout << *p << " ";
p++;
}
cout << endl;
// Преобразование списка x1.
p = transform(x1.begin(), x1.end(), x1.begin(), xform);
cout << "Преобразованный список x1: ";
p = x1.begin();
while(p != x1.end()) {
cout << *p << " ";
p++;
}
return 0;
}
При выполнении эта программа генерирует такие результаты.
Исходный список x1: 0 1 2 3 4 5 6 7 8 9
Преобразованный список x1: 0 1 4 9 16 25 36 49 64 81
Как видите, каждый элемент в списке x1 теперь возведен в квадрат.
Исследование алгоритмов
Описанные выше алгоритмы представляют собой только малую часть всего содержимого библиотеки STL. И конечно же, вам стоит самим исследовать другие алгоритмы. Заслуживают внимания многие, например set_union() и set_dif erence(). Они предназначены для обработки содержимого такого контейнера, как множество. Интересны также алгоритмы next_permutation() и prev_permutation(). Они создают следующую и предыдущую перестановки элементов заданной последовательности. Время, затраченное на изучение алгоритмов библиотеки STL, — это время, потраченное не зря!
Класс string
Класс string обеспечивает альтернативу для строк с завершающим нулем. Как вы знаете, C++ не поддерживает встроенный строковый тип. Однако он предоставляет два способа обработки строк. Во-первых, для представления строк можно использовать традиционный символьный массив с завершающим нулем. Строки, создаваемые таким способом (он вам уже знаком), иногда называют С-строками. Вовторых, можно использовать объекты класса string, и именно этот способ рассматривается в данном разделе.
В действительности класс string представляет собой специализацию более общего шаблонного класса basic_string. Существует две специализации типа basic_string: тип string, который поддерживает 8-битовые символьные строки, и тип wstring, который поддерживает строки, образованные двухбайтовыми символами. Чаще всего в обычном программировании используются строковые объекты типа string. Для использования строковых классов C++ необходимо включить в программу заголовок <string>.
Прежде чем рассматривать класс string, важно понять, почему он является частью С++- библиотеки. Стандартные классы не сразу были добавлены в определение языка C++. На самом деле каждому нововведению предшествовали серьезные дискуссии и жаркие споры. При том, что C++ уже содержит поддержку строк в виде массивов с завершающим нулем, включение класса string в C++, на первый взгляд, может показаться исключением из этого правила. Но это далеко не так. И вот почему: строки с завершающим нулем нельзя обрабатывать стандартными С++-операторами, и их нельзя использовать в обычных С++- выражениях. Рассмотрим, например, следующий фрагмент кода.
char s1 [80], s2[80], s3[80];
s1 = "один"; // так делать нельзя
s2 = "два"; // так делать нельзя
s3 = s1 + s2; // ошибка
Как отмечено в комментариях, в C++ невозможно использовать оператор присваивания для придания символьному массиву нового значения (за исключением инструкции инициализации), а также нельзя применять оператор "+" для конкатенации двух строк. Эти операции можно выполнить с помощью библиотечных функций.
strcpy(s1, "one");
strcpy(s2, "two");
strcpy(s3, s1);
strcat(s3, s2);
Поскольку символьный массив с завершающим нулем формально не является самостоятельным типом данных, к нему нельзя применить С++-операторы. Это лишает "изящества" даже самые элементарные операции со строками. И именно неспособность обрабатывать строки с завершающим нулем с помощью стандартных С++-операторов привела к разработке стандартного строкового класса. Вспомните: создавая класс в C++, мы определяем новый тип данных, который можно полностью интегрировать в С++-среду. Это, конечно же, означает, что для нового класса можно перегружать операторы. Следовательно, вводя в язык стандартный строковый класс, мы создаем возможность для обработки строк так же, как и данных любого другого типа, а именно посредством операторов.
Однако существует еще одна причина, оправдывающая создание стандартного класса string: безопасность. Руками неопытного или неосторожного программиста очень легко обеспечить выход за границы массива, который содержит строку с завершающим нулем. Рассмотрим, например, стандартную функцию копирования strcpy(). Эта функция не предусматривает механизм проверки факта нарушения границ массива-приемника. Если исходный массив содержит больше символов, чем может принять массив-приемник, то в результате этой ошибки очень вероятен полный отказ системы. Как будет показано ниже, стандартный класс string не допускает возникновения подобных ошибок.
Итак, существует три причины для включения в C++ стандартного класса string: непротиворечивость данных (строка теперь определяется самостоятельным типом данных), удобство (программист может использовать стандартные С++-операторы) и безопасность (границы массивов отныне не будут нарушаться). Следует иметь в виду, что все выше перечисленное не означает, что вы должны отказываться от использования обычных строк с завершающим нулем. Они по-прежнему остаются самым эффективным средством реализации строк. Но если скорость не является для вас определяющим фактором, использование нового класса string даст вам доступ к безопасному и полностью интегрированному способу обработки строк.
И хотя класс string традиционно не воспринимается как часть библиотеки STL, он, тем не менее, представляет собой еще один контейнерный класс, определенный в C++. Это означает, что он поддерживает алгоритмы, описанные в предыдущем разделе. При этом строки имеют дополнительные возможности. Для получения доступа к классу string необходимо включить в программу заголовок <string>.
Класс string очень большой, он содержит множество конструкторов и функций-членов. Кроме того, многие функции-члены имеют несколько перегруженных форм. Поскольку в одной главе невозможно рассмотреть все содержимое класса string, мы обратим ваше внимание только на самые популярные его средства. Получив общее представление о работе класса string, вы сможете легко разобраться в остальных его возможностях самостоятельно.
Прототипы трех самых распространенных конструкторов класса string имеют следующий вид.
string();
string(const char *str);
string (const string &str);
Первая форма конструктора создает пустой объект класса string. Вторая форма создает string-объект из строки с завершающим нулем, адресуемой параметром str. Эта форма конструктора обеспечивает преобразование из строки с завершающим нулем в объект типа string. Третья создает string-объект из другого string-объекта.
Для объектов класса string определены следующие операторы.
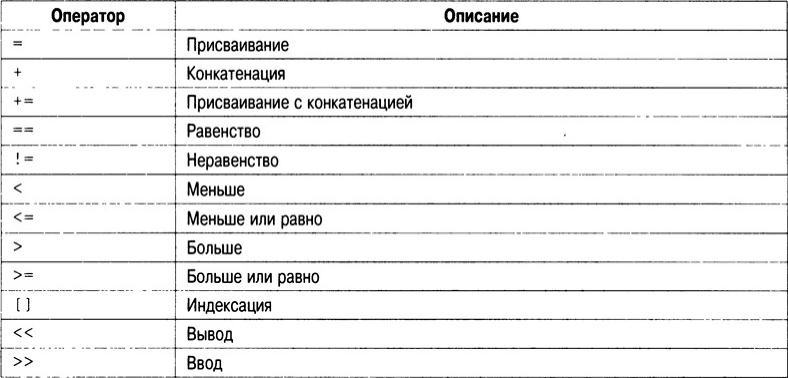
Эти операторы позволяют использовать объекты типа string в обычных выражениях и избавляют программиста от необходимости вызывать такие функции, как strcpy() или strcat(). В общем случае в выражениях можно смешивать string-объекты и строки с завершающим нулем. Например, string-объект можно присвоить строке с завершающим нулем.
Оператор "+" можно использовать для конкатенации одного string-объекта с другим или string-объекта со строкой, созданной в С-стиле (С-строкой). Другими словами, поддерживаются следующие операции.
string-объект + string-объект
string-объект + С-строка
С-строка + string-объект
Оператор "+" позволяет также добавлять символ в конец строки. В классе string определена константа npos, которая равна -1. Она представляет размер строки максимально возможной длины.
Строковый класс C++ существенно облегчает обработку строк. Например, используя string-объекты, можно применять оператор присваивания для назначения string-объекту строки в кавычках, оператор "+" — для конкатенации строк и операторы сравнения — для сравнения строк. Выполнение этих операций демонстрируется в следующей программе
// Программа демонстрации обработки строк.
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str1("Класс string позволяет эффективно ");
string str2("обрабатывать строки.");
string str3;
// Присваивание string-объекта.
str3 = str1;
cout << str1 << "\n" << str3 << "\n";
// Конкатенация двух string-объектов.
str3 = str1 + str2;
cout << str3 << "\n";
// Сравнение string-объектов.
if(str3 > str1) cout << "str3 > str1\n";
if(str3 == str1 + str2)
cout << "str3 == str1+str2\n";
/* Объекту класса string можно также присвоить обычную строку.
*/
str1 = "Это строка с завершающим нулем.\n";
cout << str1;
/* Создание string-объекта с помощью другого string-объекта.
*/
string str4 (str1);
cout << str4;
// Ввод строки.
cout << "Введите строку: ";
cin >> str4;
cout << str4;
return 0;
}
При выполнении эта программа генерирует такие результаты.
Класс string позволяет эффективно
Класс string позволяет эффективно
Класс string позволяет эффективно обрабатывать строки.
str3 > str1
str3 == str1+str2
Это строка с завершающим нулем.
Это строка с завершающим нулем.
Введите строку: Привет
Привет
Обратите внимание на то, как легко теперь выполняется обработка строк. Например, оператор "+" используется для конкатенации строк, а оператор ">" — для сравнения двух строк. Для выполнения этих операций с использованием С-стиля обработки строк, т.е. использования строк с завершающим нулем, пришлось бы применять менее удобные средства, а именно вызывать функции strcat() и strcmp(). Поскольку С++-объекты типа string можно свободно смешивать с С-строками, их (string-объекты) можно использовать в любой программе не только безо всякого ущерба для эффективности, но даже с заметным выигрышем
Важно также отметить, что в предыдущей программе размер строк не задается. Объекты типа string автоматически получают размер, нужный для хранения заданной строки. Таким образом, при выполнении операций присваивания или конкатенации строк строкаприемник увеличится по длине настолько, насколько это необходимо для хранения нового содержимого строки. При обработке string-объектов невозможно выйти за границы строки. Именно этот динамический аспект string-объектов выгодно отличает их от строк с завершающим нулем (которые часто страдают от нарушения границ).
Обзор функций-членов класса string
Если самые простые операции со строками можно реализовать с помощью операторов, то при выполнении более сложных не обойтись без функций-членов класса string. Класс string содержит слишком много функций-членов, мы же рассмотрим здесь только самые употребительные из них.
Важно! Поскольку класс string— контейнер, он поддерживает такие обычные контейнерные функции, как begin(), end() и size().
Основные манипуляции над строками
Чтобы присвоить одну строку другой, используйте функцию assign(). Вот как выглядят два возможных формата ее реализации.
string &assign(const string &strob, size_type start, size_type
num);
string &assign(const char *str, size_type num);
Первый формат позволяет присвоить вызывающему объекту num символов из строки, заданной параметром strob, начиная с индекса start. При использовании второго формата вызывающему объекту присваиваются первые num символов строки с завершающим нулем, заданной параметром str. В каждом случае возвращается ссылка на вызывающий объект. Конечно, гораздо проще для присвоения одной полной строки другой использовать оператор "=". О функции-члене assign() вспоминают, в основном, тогда, когда нужно присвоить только часть строки.
С помощью функции-члена append() можно часть одной строки присоединить в конец другой. Два возможных формата ее реализации имеют следующий вид.
string &append(const string &strob, size_type start, size_type
num);
string &append(const char *str, size_type num);
Здесь при использовании первого формата num символов из строки, заданной параметром strob, начиная с индекса start, будет присоединено в конец вызывающего объекта. Второй формат позволяет присоединить в конец вызывающего объекта первые num символов строки с завершающим нулем, заданной параметром str. В каждом случае возвращается ссылка на вызывающий объект. Конечно, гораздо проще для присоединения одной полной строки в конец другой использовать оператор Функция же append() применяется тогда, когда необходимо присоединить в конец вызывающего объекта только часть строки.
Вставку или замену символов в строке можно выполнять с помощью функций-членов insert() и replace(). Вот как выглядят прототипы их наиболее употребительных форматов.
string &insert(size_type start, const string &strob);
string &insert(size_type start, const string &strob, size_type
insStart, size_type num);
string &replace(size_type start, size_type num, const string
&strob);
string &replace(size_type start, size_type orgNum, const string
&strob, size_type replaceStart, size_type replaceNum);
Первый формат функции insert() позволяет вставить строку, заданную параметром strob, в позицию вызывающей строки, заданную параметром start. Второй формат функции insert() предназначен для вставки num символов из строки, заданной параметром strob, начиная с индекса insStart, в позицию вызывающей строки, заданную параметром start.
Первый формат функции replace() служит для замены num символов в вызывающей строке, начиная с индекса start, строкой, заданной параметром strob. Второй формат позволяет заменить orgNum символов в вызывающей строке, начиная с индекса start, replaceNum символами строки, заданной параметром strob, начиная с индекса replaceStart. В каждом случае возвращается ссылка на вызывающий объект.
Удалить символы из строки можно с помощью функции erase(). Один из ее форматов выглядит так:
string &erase(size_type start = 0, size_type num = npos);
Эта функция удаляет num символов из вызывающей строки, начиная с индекса start. Функция возвращает ссылку на вызывающий объект.
ункция возвращает ссылку на вызывающий объект. Использование функций insert(), erase() и replace() демонстрируется в следующей программе.
// Демонстрация использования функций insert(), erase() и
replace().
#include <iostream>
#include <string>
using namespace std;
int main()
{
string str1("Это простой тест.");
string str2("ABCDEFG");
cout << "Исходные строки:\n";
cout << "str1: " << str1 << endl;
cout << "str2: " << str2 << "\n\n";
// Демонстрируем использование функции insert().
cout << "Вставляем строку str2 в строку str1:\n";
str1.insert(5, str2);
cout << str1 << "\n\n";
// Демонстрируем использование функции erase().
cout << "Удаляем 7 символов из строки str1:\n";
str1.erase(5, 7);
cout << str1 <<"\n\n";
// Демонстрируем использование функции replace().
cout << "Заменяем 2 символа в str1 строкой str2:\n";
str1.replace(5, 2, str2);
cout << str1 << endl;
return 0;
}
Результаты выполнения этой программы таковы.
Исходные строки:
str1: Это простой тест.
str2: ABCDEFG
Вставляем строку str2 в строку str1:
Это пABCDEFGростой тест.
Удаляем 7 символов из строки str1:
Это простой тест.
Заменяем 2 символа в str1 строкой str2:
Это пABCDEFGстой тест.
Поиск в строке
В классе string предусмотрено несколько функций-членов, которые осуществляют поиск. Это, например, такие функции, как find() и rfind(). Рассмотрим прототипы самых употребительных версий этих функций.
size_type find(const string &strob, size_type start=0) const;
size_type rfind(const string &strob, size_type start=npos)
const;
Функция find(), начиная с позиции start, просматривает вызывающую строку на предмет поиска первого вхождения строки, заданной параметром strob. Если поиск успешен, функция find() возвращает индекс, по которому в вызывающей строке было обнаружено совпадение. Если совпадения не обнаружено, возвращается значение npos. Функция rfind() выполняет то же действие, но с конца. Начиная с позиции start, она просматривает вызывающую строку в обратном направлении на предмет поиска первого вхождения строки, заданной параметром strob (т.е. она находит в вызывающей строке последнее вхождение строки, заданной параметром strob). Если поиск прошел удачно, функция rfind() возвращает индекс, по которому в вызывающей строке было обнаружено совпадение. Если совпадения не обнаружено, возвращается значение npos
Рассмотрим короткий пример использования функции find().
#include <iostream>
#include <string>
using namespace std;
int main()
{
int i;
string s1 ="Класс string облегчает обработку строк.";
string s2;
i = s1.find("string");
if(i != string::npos) {
cout << "Совпадение обнаружено в позиции " << i<< endl;
cout << "Остаток строки таков: ";
s2.assign (s1, i, s1.size());
cout << s2;
}
return 0;
}
Программа генерирует такие результаты.
Совпадение обнаружено в позиции 6
Остаток строки таков: string облегчает обработку строк.
Сравнение строк
Чтобы сравнить полное содержимое одного string-объекта с другим, обычно используются описанные выше перегруженные операторы отношений. Но если нужно сравнить часть одной строки с другой, вам придется использовать функцию-член compare().
int compare(size_type start, size_type num, const string &strob)
const;
Функция compare() сравнивает с вызывающей строкой num символов строки, заданной параметром strob, начиная с индекса start. Если вызывающая строка меньше строки strob, функция compare() возвратит отрицательное значение. Если вызывающая строка больше строки strob, она возвратит положительное значение. Если строка strob равна вызывающей строке, функция compare() возвратит нуль.
Получение строки с завершающим нулем
Несмотря на неоспоримую полезность объектов типа string, возможны ситуации, когда вам придется получать из такого объекта символьный массив с завершающим нулем, т.е. его версию С-строки. Например, вы могли бы использовать string-объект для создания имени файла. Но, открывая файл, вам нужно задать указатель на стандартную строку с завершающим нулем. Для решения этой проблемы и используется функция-член c_str(). Вот как выглядит ее прототип:
const char *c_str() const;
Эта функция возвращает указатель на С-версию строки (т.е. на строку с завершающим нулевым символом), которая содержится в вызывающем объекте типа string. Полученная строка с завершающим нулем изменению не подлежит. Кроме того, после выполнения других операций над этим string-объектом допустимость применения полученной С-строки не гарантируется
Хранение строк в других контейнерах
Поскольку класс string определяет тип данных, можно создать контейнеры, которые будут содержать объекты типа string. Рассмотрим, например, более удачный вариант программы-словаря, которая была показана выше.
/* Использование отображения string-объектов для создания
словаря.
*/
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main()
{
map<string, string> dictionary;
dictionary.insert( pair<string, string> ("дом", "Место
проживания."));
dictionary.insert( pair<string, string> ("клавиатура",
"Устройство ввода данных."));
dictionary.insert( pair<string, string> ("программирование",
"Процесс создания программы."));
dictionary.insert( pair<string, string> ("STL", "Standard
Template Library"));
string s;
cout << "Введите слово: ";
cin >> s;
map<string, string>::iterator p;
p = dictionary.find(s);
if(p != dictionary.end())
cout << "Определение: " << p->second;
else cout << "Такого слова в словаре нет.\n";
return 0;
}
И еще об STL
Библиотека STL — важная составляющая языка C++. Многие задачи программирования можно описать, используя терминологию STL. Эта библиотека великолепно сочетает силу своих средств с гибкостью их применения. Несмотря на то что ее синтаксис немного сложноват, он быстро осваивается. Ни один уважающий себя С++-программист не может пренебречь возможностями библиотеки STL, поскольку она — не только настоящее, но и будущее С++-программирования.